RagBase - Private Chat with Your Documents
Build completely local RAG system with LangChain, Streamlit, and Llama 3.1
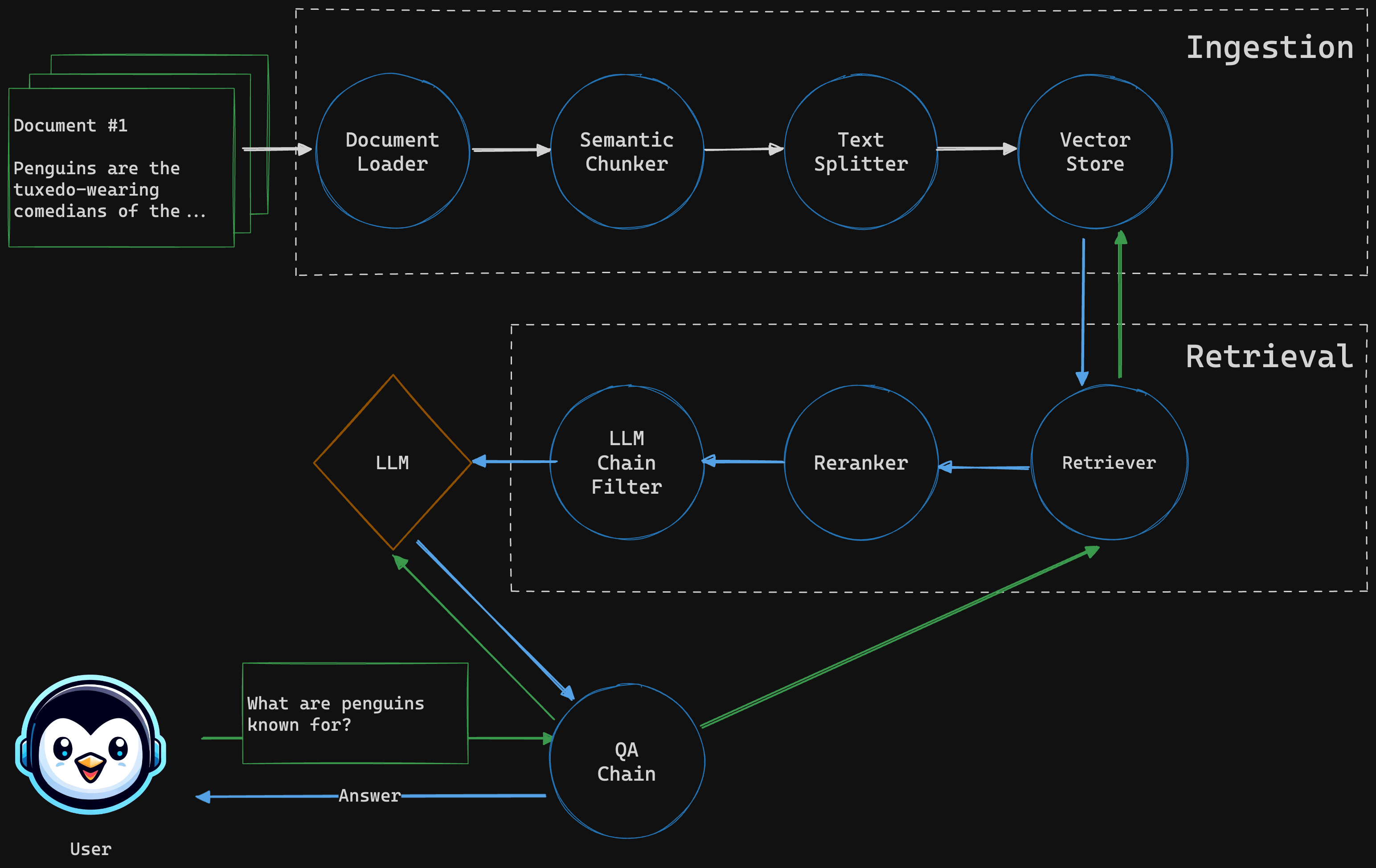
Welcome to the RAGBase project! You’ll learn how to create a Retrieval-Augmented Generation (RAG) system using Python and Streamlit. The goal is to help you build a powerful and efficient tool that can extract information from your documents and provide accurate answers to your questions - without leaving your local environment.
Want to try the complete app? Check out the live demo at RagBase Streamlit Cloud
This tutorial will cover:
Tutorial Goals
In this tutorial you will:
- Learn how to extract text from PDF documents
- Ingest documents into a vector store, including splitting
- Retrieve, rerank and filter related documents
- Build QA chain that connects the retriever, the LLM and the UI
- Create user interface using Streamlit
RagBase is a system designed to process documents, extract text, and store it in a vector store. The system retrieves relevant documents when a user asks a question, generates an answer, and displays the relevant sources. Additionally, it maintains the chat history and provides it to the LLM along with the context. The user interface, built with Streamlit, allows users to upload documents, ask questions, and receive answers in a chat-like format. The entire system is designed to operate locally, ensuring data privacy and security.
By the end of this tutorial, you’ll have RagBase up and running and understand the inner workings of the system. Let’s dive in!