Better Context for your RAG with Contextual Retrieval
What if your chunks in RAG were providing better context? Let's explore how to use contextual retrieval to enhance your RAG systems.
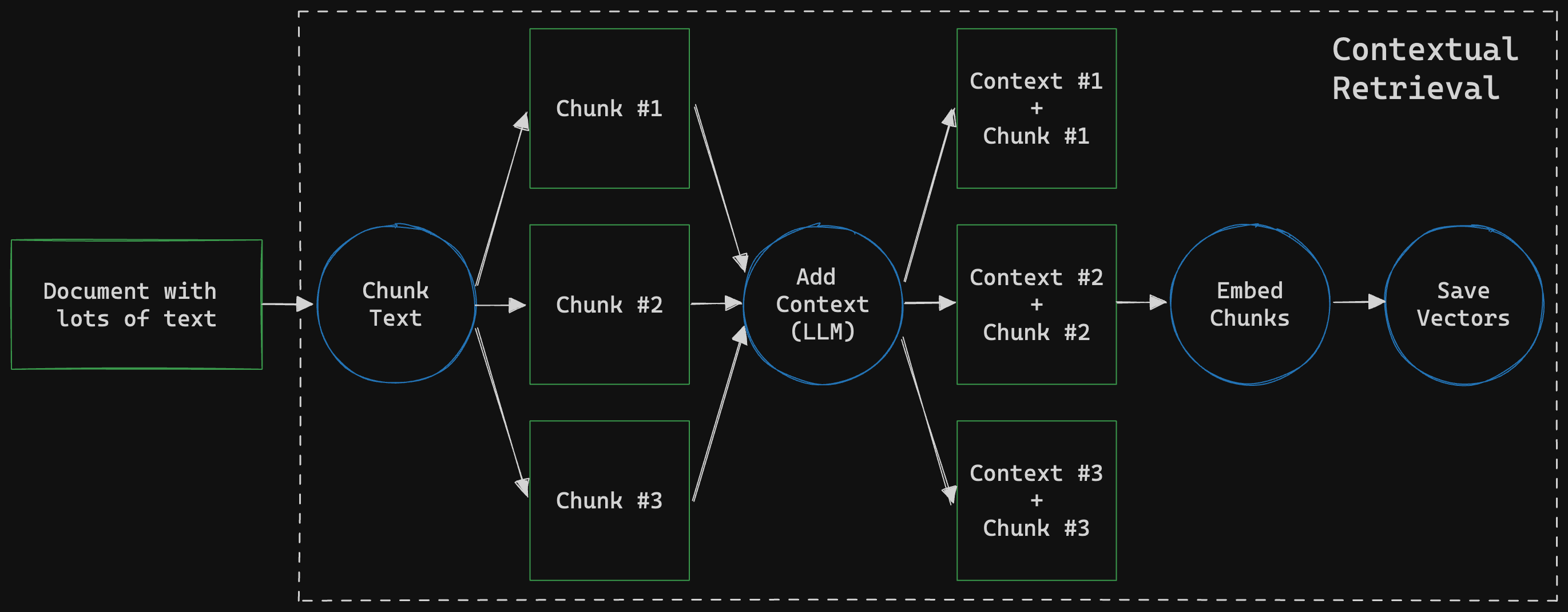
No matter how advanced your model (LLM) is, if the context chunks don't provide the right information, the model won't generate accurate answers. In this tutorial, we'll explore a technique called contextual retrieval to improve the quality of context chunks in your RAG systems.
To give you a better understanding, let's start with a simple example. Imagine you have a document with multiple chunks, and you want to ask a question based on one of them. Let's have a look at a sample chunk:
For more information, please refer to[the documentation of `vllm`](https://docs.vllm.ai/en/stable/).
Now, you can have fun with Qwen2.5 models.This is a good example of a chunk that could benefit from additional context. In itself, it's not very informative. Let's look at the one with added context:
For more information, please refer to[the documentation of `vllm`](https://docs.vllm.ai/en/stable/).
Now, you can have fun with Qwen2.5 models.The chunk is situated at the end of the document, following the section ondeploying Qwen2.5 models with vLLM, and serves as a concluding remarkencouraging users to explore the capabilities of Qwen2.5 models.You can imagine when the model receives this chunk, it has a better understanding of the context and can provide more accurate answers. Let's build the pipeline to create these chunks.
What is Contextual Retrieval?
Contextual Retrieval (introduced by Anthropic1) addresses a common issue in traditional Retrieval-Augmented Generation (RAG) systems: individual text chunks often lack enough context for accurate retrieval and understanding.
Contextual Retrieval enhances each chunk by adding specific, explanatory context before embedding or indexing it. This preserves the relationship between the chunk and its broader document, significantly improving the system's ability to retrieve and use the most relevant information.
According to Anthropic's experiments:
- Contextual Embeddings reduced the top-20 chunk retrieval failure rate by 35%.
- Combining Contextual Embeddings with Contextual BM25 further reduced the failure rate by 49%.
These improvements highlight the potential of Contextual Retrieval to boost the performance of AI-powered question-answering systems, making them more accurate and contextually aware.
What We'll Build
We'll use two example documents to demonstrate how Contextual Retrieval can improve a question-answering system. Our system will:
- Break the documents into smaller chunks.
- Add contextual information to each chunk, embed them, and store them in a database.
- Perform similarity searches to find the most relevant context.
- Use an LLM to generate answers to user questions based on the retrieved context.
Setting Up the Environment
Project Setup
Want to follow along? All code for the bootcamp is available at this Github repository
First, let's install the necessary libraries:
pip install -Uqqq pip --progress-bar offpip install -qqq fastembed==0.3.6 --progress-bar offpip install -qqq sqlite-vec==0.1.2 --progress-bar offpip install -qqq groq==0.11.0 --progress-bar offpip install -qqq langchain-text-splitters==0.3.0 --progress-bar offNow, let's import the required modules:
import sqlite3from textwrap import dedentfrom typing import List
import sqlite_vecfrom fastembed import TextEmbeddingfrom google.colab import userdatafrom groq import Groqfrom groq.types.chat import ChatCompletionMessagefrom langchain_text_splitters import RecursiveCharacterTextSplitterfrom sqlite_vec import serialize_float32from tqdm import tqdmLanguage Model Setup
We'll be using Llama 3.1 through the Groq API. First, let's set up the client:
client = Groq(api_key=userdata.get("GROQ_API_KEY"))MODEL = "llama-3.1-70b-versatile"TEMPERATURE = 0Next, we'll create a helper function to interact with the model. This function will take a prompt and an optional message history:
def call_model(prompt: str, messages=[]) -> ChatCompletionMessage: messages.append({ "role": "user", "content": prompt, }) response = client.chat.completions.create( model=MODEL, messages=messages, temperature=TEMPERATURE, ) return response.choices[0].message.contentThis function sends a prompt to the model and returns the model's response. You can also pass a message history to maintain the conversation's context.
Database Setup
We'll use SQLite with the sqlite-vec extension2 to store our documents and their embeddings. Here's how to set up the database:
db = sqlite3.connect("readmes.sqlite3")db.enable_load_extension(True)sqlite_vec.load(db)db.enable_load_extension(False)After connecting to the database, let's create the necessary tables:
db.execute("""CREATE TABLE documents( id INTEGER PRIMARY KEY AUTOINCREMENT, text TEXT);""")
db.execute("""CREATE TABLE chunks( id INTEGER PRIMARY KEY AUTOINCREMENT, document_id INTEGER, text TEXT, FOREIGN KEY(document_id) REFERENCES documents(id));""")
db.execute(f"""CREATE VIRTUAL TABLE chunk_embeddings USING vec0( id INTEGER PRIMARY KEY, embedding FLOAT[{document_embeddings[0].shape[0]}]);""")Here's a breakdown of the tables:
documents: Stores the full text of each document.chunks: Stores smaller chunks of text split from the documents.chunk_embeddings: Stores the embeddings of each chunk for similarity searches.
This database setup allows us to store, retrieve, and embed chunks efficiently, making it easy to perform similarity searches later.
Create Chunks
To break down the documents into manageable chunks for better context retrieval, we'll follow these steps:
- Split the document text into smaller chunks.
- Add contextual information to each chunk.
- Embed each chunk and store it in the database along with the text.
The documents we'll use are the READMEs of the Qwen 2.5 models and the LangGraph project.
First, let's save the documents in the database:
documents = [qwen_doc, langgraph_doc]
with db: for doc in documents: db.execute("INSERT INTO documents(text) VALUES(?)", [doc])To split the documents into smaller chunks, we'll use the RecursiveCharacterTextSplitter3 from LangChain:
text_splitter = RecursiveCharacterTextSplitter(chunk_size=2048, chunk_overlap=128)We can now create the chunks and store them in the database:
with db: document_rows = db.execute("SELECT id, text FROM documents").fetchall() for row in document_rows: doc_id, doc_text = row chunks = text_splitter.split_text(doc_text) contextual_chunks = create_contextual_chunks(chunks, doc_text) save_chunks(contextual_chunks)To give each chunk additional context, we'll generate short summaries using the following prompt:
CONTEXTUAL_EMBEDDING_PROMPT = """Here is the chunk we want to situate within the whole document:<chunk>{chunk}</chunk>
Here is the content of the whole document:<document>{document}</document>
Please provide a short, succinct context to situate this chunk within the overall document to improve search retrieval. Respond only with the context."""Here's how the function works:
def create_contextual_chunks(chunks: List[str], document: str) -> List[str]: contextual_chunks = [] for chunk in chunks: prompt = CONTEXTUAL_EMBEDDING_PROMPT.format(chunk=chunk, document=document) chunk_context = call_model(prompt) contextual_chunks.append(f"{chunk}\n{chunk_context}") return contextual_chunksThis function sends each chunk along with the entire document to the model, which generates a short context that improves search retrieval. The context is then prepended to the chunk.
We'll use the fastembed4 library to create embeddings for our document chunks:
embedding_model = TextEmbedding()Finally, let's save the chunks and their embeddings in the database:
def save_chunks(chunks: List[str]): chunk_embeddings = list(embedding_model.embed(chunks)) for chunk, embedding in zip(chunks, chunk_embeddings): result = db.execute( "INSERT INTO chunks(document_id, text) VALUES(?, ?)", [doc_id, chunk] ) chunk_id = result.lastrowid db.execute( "INSERT INTO chunk_embeddings(id, embedding) VALUES (?, ?)", [chunk_id, serialize_float32(embedding)], )This function saves each chunk along with its embedding to the chunks and chunk_embeddings tables in the database. The serialize_float32 function is used to store the embedding in a format that can be efficiently retrieved later.
Retrieving Context
Once the chunks and their embeddings are stored in the database, we can retrieve the most relevant context for a given query. Here's the function to do that:
def retrieve_context(query: str, k: int = 3, embedding_model: TextEmbedding = embedding_model) -> str: query_embedding = list(embedding_model.embed([query]))[0] results = db.execute( """ SELECT chunk_embeddings.id, distance, text FROM chunk_embeddings LEFT JOIN chunks ON chunks.id = chunk_embeddings.id WHERE embedding MATCH ? AND k = ? ORDER BY distance """, [serialize_float32(query_embedding), k], ).fetchall() return "\n-----\n".join([item[2] for item in results])- Query Embedding: The function first converts the input query into an embedding using the
embedding_model. - Database Query: It then retrieves the top
kchunks with embeddings most similar to the query by:- Calculating the cosine similarity between the query embedding and the stored chunk embeddings (this is handled by the
sqlite-vecextension). - Ordering the results by the similarity
distance(where a lower distance means a closer match).
- Calculating the cosine similarity between the query embedding and the stored chunk embeddings (this is handled by the
- Return Result: The retrieved text chunks are concatenated into a single string, separated by
\n-----\nfor clarity.
Generating Answers
To generate answers, we'll combine a system prompt with the retrieved context. This ensures the model provides accurate and contextually relevant responses.
The system prompt sets the tone and expectations for how the model should respond:
SYSTEM_PROMPT = """You're an expert AI/ML engineer with a background in software development.You're answering questions about technical topics and projects.If you don't know the answer, simply state that you don't know.Keep your answers brief and to the point. Be kind and respectful.
Use the provided context for your answers. The most relevant information isat the top. Each piece of information is separated by ---."""Here's the function that ties everything together:
def ask_question(query: str) -> str: messages = [ { "role": "system", "content": SYSTEM_PROMPT, }, ] context = retrieve_context(query) prompt = dedent( f"""Use the following information:
```
{context}
```
to answer the question:{query} """ ) return call_model(prompt, messages), context-
Set Up the System Prompt: The
SYSTEM_PROMPTguides the model on how to answer questions—encouraging brief, respectful, and context-aware responses. If the model doesn't know the answer, it's instructed to admit that. -
Retrieve Relevant Context: The
retrieve_context(query)function fetches the most relevant context chunks from the database for the given query. -
Create the Final Prompt: The retrieved context is inserted into the prompt, which then instructs the model to use that information to answer the user's query.
-
Call the Model: The
call_model(prompt, messages)function sends the prompt to the LLM and generates the answer. -
Return the Response: The function returns the model's generated answer along with the retrieved context (optional for review).
To answer a question, you would call the function like this:
answer, context = ask_question("How does Contextual Retrieval improve RAG performance?")print("Answer:", answer)print("Context used:", context)This provides both the answer and the context used by the model to generate the response.
Using the RAG
Now we can try out our system with some questions. Let's start by asking a simple question about the Qwen model:
query = "How many parameters does Qwen have?"response, context = ask_question(query)print(response)Qwen2.5 models are available in various sizes, with the number of parametersranging from 0.5B to 72B. The specific model mentioned in the text has 32.5Bparameters, with 31.0B non-embedding parameters.Very good, seems like the model is providing accurate information based on the context retrieved. Let's try something a bit more technical:
query = "How should one deploy Qwen model on a private server?"response, context = ask_question(query)print(response)To deploy Qwen2.5 on a private server, you can use vLLM, a fast and easy-to-useframework for LLM inference and serving. First, install `vllm>=0.4.0` usingpip. Then, run the following command to build up a vLLM service:
```bashpython -m vllm.entrypoints.openai.api_server --model Qwen/Qwen2.5-7B-Instruct```Alternatively, with vllm>=0.5.3, you can use:
vllm serve Qwen/Qwen2.5-7B-InstructThis will start a service that you can interact with using the OpenAI API.
This is a nice summary of the deployment part of the document. Let's try one more question:
query = "I have a RTX 4090 (24GB). Which version of the model can I run with good inference speed?"response, context = ask_question(query)print(response)Based on the provided information, the model sizes available for Qwen2.5 are0.5B, 1.5B, 3B, 7B, 14B, 32B, and 72B.
Considering your RTX 4090 has 24GB of memory, you can likely run the 7B or 14Bmodels with good inference speed. However, the 14B model might be pushing thelimits of your GPU's memory, so the 7B model would be a safer choice.
Keep in mind that the actual performance will also depend on other factors suchas your system's CPU, RAM, and the specific use case.This information is not found within the document, but the model has provided a good answer based on the context retrieved and its reasoning capabilities. For more questions and answers, have a look at the Google Colab Notebook.
Conclusion
You've built a RAG system that uses:
- Contextual Chunking: Breaks documents into meaningful chunks, improving retrieval accuracy.
- Efficient Similarity Search: Uses vector embeddings to find the most relevant information.
- Language Model Integration: Leverages a powerful model to generate natural language responses based on retrieved context.
As you continue refining this system, consider enhancing it with:
- Caching: For faster response times and improved performance (possible if using prompt caching).
- Multi-Document Support: Expanding to handle more and different types of documents.
- User-Friendly Interface: Making the system accessible for non-technical users.
Let me know what you're going to build with this system!