Fine-tuning Llama 2 on a Custom Dataset
Can you make LLMs work better for your specific task? Yes, you can! In this tutorial, you’ll learn how to fine-tune Llama 21 on a custom dataset using the QLoRA2 technique. We’ll use a dataset of conversations between a customer and a support agent over Twitter. The goal is to summarize the conversation and compare it to the summary provided by the dataset.
Join the AI BootCamp!
Ready to dive into the world of AI and Machine Learning? Join the AI BootCamp to transform your career with the latest skills and hands-on project experience. Learn about LLMs, ML best practices, and much more!
We’ll start by installing the required libraries. We’ll choose a dataset and have a look at some specific examples from it. Then, we’ll fine-tune Llama 2 (7b base model) on the dataset using the QLoRA technique and a single GPU. Finally, we’ll compare the results of the fine-tuned model with the base Llama 2 model.
In this part, we will be using Jupyter Notebook to run the code. If you prefer to follow along, you can find the notebook on GitHub: GitHub Repository
Why Fine-tune an LLM?
Prompts are a convenient way to start using Large Language Models (LLMs), enabling you to tap into the power of Generative AI with minimal effort. However, relying solely on prompts for the long term can lead to several issues:
- High Cost: Complex prompts with extensive context can accumulate a large number of tokens, resulting in increased costs.
- High Latency: Lengthy prompts, especially when chained, can introduce significant delays, negatively affecting user experience.
- Hallucinations: Prompt-based approaches may struggle with providing concise and truthful answers due to insufficient context.
- Meh Results: As foundation models continue to improve, the competitive advantage offered by prompts diminishes. Great results often require fine-tuned models trained on (your) specific data.
If you’ve encountered these issues, fine-tuning might be a solution. While other techniques like vector search, caching, and prompt chaining can help with some problems, fine-tuning is often the most effective and versatile option.
Benefits of Fine-Tuning:
- Improved Performance: Fine-tuning tailors the model to your specific needs, resulting in better task performance.
- Lower Cost and Latency: Fine-tuning can reduce the number of tokens required to generate a response, resulting in lower costs and latency.
- Enhanced Privacy: Fine-tuning with your own data and deployment adds an extra layer of privacy.
However, there are challenges:
- Time and Resource Consuming: Fine-tuning is a lengthy process and requires a lot of resources (Huge GPUs), involving training, optimization, and evaluation.
- Expertise: Achieving optimal results requires expertise in data handling, training, and inference techniques.
- Lack of Contextual Knowledge: Fine-tuned models excel in specific tasks but may lack the versatility of closed-source models like GPT-4.
When to Fine-Tune an LLM?
When prompting doesn’t work for you and you have the resources to fine-tune a model. It’s that simple!
By resources I mean:
- compute power (GPUs)
- time and expertise (know WTF are you doing)
- high quality data - labels if you are doing summarization, text extraction or other task that requires labels
Base (non-instruction tuned) LLM models can be trained in a supervised manner. The process is similar to training a traditional deep learning model. You need to prepare the data, choose a model, fine-tune it, and evaluate the results. The main difference is that you’ll be using text as input and output.
Of course, you can fine-tune and instruction tuned model, but that would require a dataset of instructions. The process is similar to fine-tuning a base model, but you’ll need to use proper prompt formatting.
Setup
We’ll use some common libraries like PyTorch and HuggingFace Transformers. Besides those, we’ll need some additional libraries for fine-tuning the Llama 2 model:
!pip install -Uqqq pip --progress-bar off
!pip install -qqq torch==2.0.1 --progress-bar off
!pip install -qqq transformers==4.32.1 --progress-bar off
!pip install -qqq datasets==2.14.4 --progress-bar off
!pip install -qqq peft==0.5.0 --progress-bar off
!pip install -qqq bitsandbytes==0.41.1 --progress-bar off
!pip install -qqq trl==0.7.1 --progress-bar offThe bitsandbytes3 library will help us load the model in 4 bits. The
peft4 library gives us tools to use the LoRA technique. The trl5
library provides a trainer class that we’ll use to fine-tune the model.
Next, let’s add the required imports:
import json
import re
from pprint import pprint
import pandas as pd
import torch
from datasets import Dataset, load_dataset
from huggingface_hub import notebook_login
from peft import LoraConfig, PeftModel
from transformers import (
AutoModelForCausalLM,
AutoTokenizer,
BitsAndBytesConfig,
TrainingArguments,
)
from trl import SFTTrainer
DEVICE = "cuda:0" if torch.cuda.is_available() else "cpu"
MODEL_NAME = "meta-llama/Llama-2-7b-hf"The model we’ll use is the 7b version of Llama 2 (by Meta AI). It’s the base model (not instruction tuned), since we’ll not use it in conversational mode.
Data Preprocessing
The dataset we’ll use is a collection of conversations between a customer and a support agent over Twitter. The data itself is provided by Salesforce and is available on the HuggingFace Datasets6 hub. The dataset contains 1099 conversations, split into 879 for training, 110 for validation, and 110 for testing. Let’s load it:
dataset = load_dataset("Salesforce/dialogstudio", "TweetSumm")
datasetDatasetDict({
train: Dataset({
features: ['original dialog id', 'new dialog id', 'dialog index',
'original dialog info', 'log', 'prompt'],
num_rows: 879
})
validation: Dataset({
features: ['original dialog id', 'new dialog id', 'dialog index',
'original dialog info', 'log', 'prompt'],
num_rows: 110
})
test: Dataset({
features: ['original dialog id', 'new dialog id', 'dialog index',
'original dialog info', 'log', 'prompt'],
num_rows: 110
})
})Let’s have a look at the preview on HuggingFace Datasets Hub:
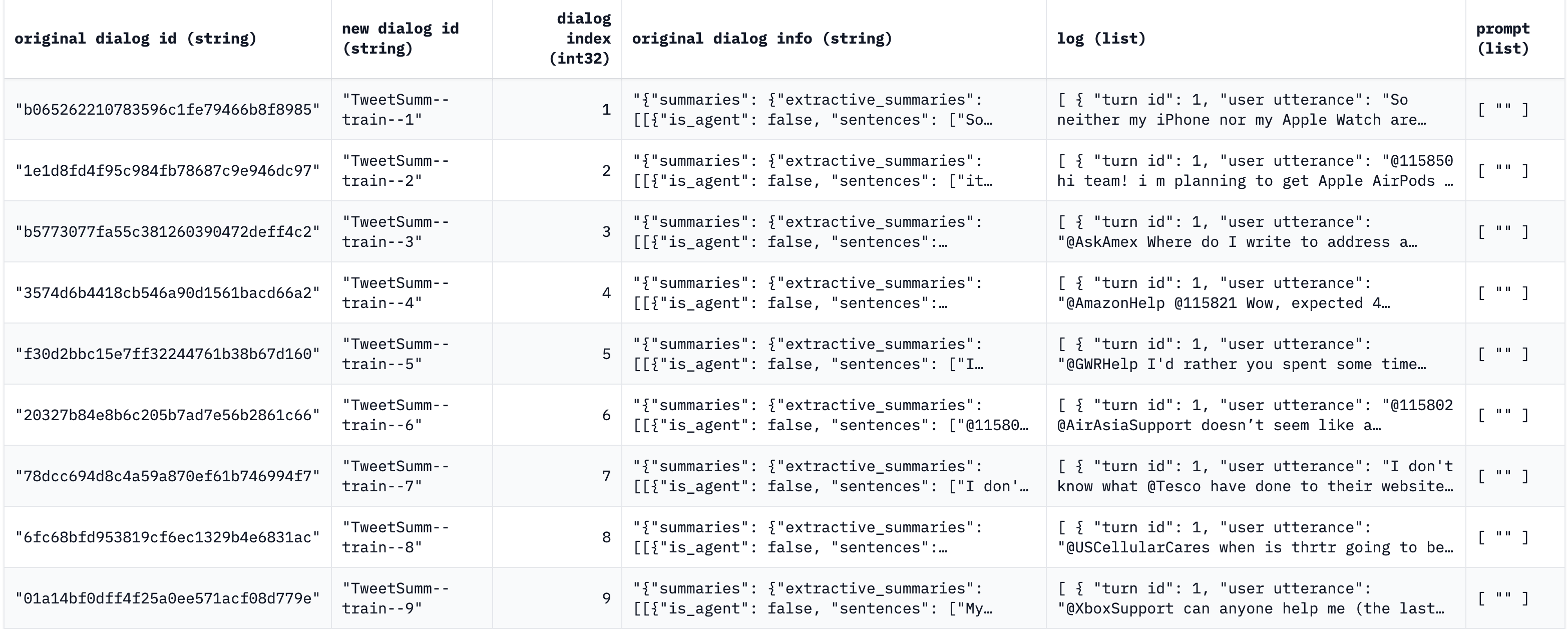
We’re primarily interested in two fields:
original dialog info- the summary of the conversation.log- the conversation itself.
Let’s write a function that extracts the summary and the conversation from a data point:
def generate_text(data_point):
summaries = json.loads(data_point["original dialog info"])["summaries"][
"abstractive_summaries"
]
summary = summaries[0]
summary = " ".join(summary)
conversation_text = create_conversation_text(data_point)
return {
"conversation": conversation_text,
"summary": summary,
"text": generate_training_prompt(conversation_text, summary),
}The summary is extracted from the structure of the data point. Here’s an example summary:
Customer enquired about his Iphone and Apple watch which is not showing his any
steps/activity and health activities. Agent is asking to move to DM and look
into it.Let’s have a look at the create_conversation_text function:
def create_conversation_text(data_point):
text = ""
for item in data_point["log"]:
user = clean_text(item["user utterance"])
text += f"user: {user.strip()}\n"
agent = clean_text(item["system response"])
text += f"agent: {agent.strip()}\n"
return text
def clean_text(text):
text = re.sub(r"http\S+", "", text)
text = re.sub(r"@[^\s]+", "", text)
text = re.sub(r"\s+", " ", text)
return re.sub(r"\^[^ ]+", "", text)The function puts together the conversation text from the log field of the
data point. It also cleans the text by removing URLs, mentions, and extra
spaces. Here’s an example conversation:
user: So neither my iPhone nor my Apple Watch are recording my steps/activity,
and Health doesn't recognise either source anymore for some reason. Any ideas?
please read the above. agent: Let's investigate this together. To start, can you
tell us the software versions your iPhone and Apple Watch are running currently?
user: My iPhone is on 11.1.2, and my watch is on 4.1. agent: Thank you. Have you
tried restarting both devices since this started happening? user: I've restarted
both, also un-paired then re-paired the watch. agent: Got it. When did you first
notice that the two devices were not talking to each other. Do the two devices
communicate through other apps such as Messages? user: Yes, everything seems
fine, it's just Health and activity. agent: Let's move to DM and look into this
a bit more. When reaching out in DM, let us know when this first started
happening please. For example, did it start after an update or after installing
a certain app?The final piece is the prompt generation function (the text we’ll use during the training):
DEFAULT_SYSTEM_PROMPT = """
Below is a conversation between a human and an AI agent. Write a summary of the conversation.
""".strip()
def generate_training_prompt(
conversation: str, summary: str, system_prompt: str = DEFAULT_SYSTEM_PROMPT
) -> str:
return f"""### Instruction: {system_prompt}
### Input:
{conversation.strip()}
### Response:
{summary}
""".strip()We’ll use Alapaca-style prompt format. Here’s the prompt from our example:
### Instruction:
Below is a conversation between a human and an AI agent. Write a summary of the
conversation.
### Input:
user: So neither my iPhone nor my Apple Watch are recording my steps/activity,
and Health doesn't recognise either source anymore for some reason. Any ideas?
please read the above. agent: Let's investigate this together. To start, can you
tell us the software versions your iPhone and Apple Watch are running currently?
user: My iPhone is on 11.1.2, and my watch is on 4.1. agent: Thank you. Have you
tried restarting both devices since this started happening? user: I've restarted
both, also un-paired then re-paired the watch. agent: Got it. When did you first
notice that the two devices were not talking to each other. Do the two devices
communicate through other apps such as Messages? user: Yes, everything seems
fine, it's just Health and activity. agent: Let's move to DM and look into this
a bit more. When reaching out in DM, let us know when this first started
happening please. For example, did it start after an update or after installing
a certain app?
### Response:
Customer enquired about his Iphone and Apple watch which is not showing his any
steps/activity and health activities. Agent is asking to move to DM and look
into it.We can now process the whole dataset using a helper function:
def process_dataset(data: Dataset):
return (
data.shuffle(seed=42)
.map(generate_text)
.remove_columns(
[
"original dialog id",
"new dialog id",
"dialog index",
"original dialog info",
"log",
"prompt",
]
)
)This uses the datasets library to shuffle the data and apply the
generate_text function to each data point. It also removes the fields we don’t
need. Let’s apply it to all splits of the dataset:
dataset["train"] = process_dataset(dataset["train"])
dataset["validation"] = process_dataset(dataset["validation"])
datasetDatasetDict({
train: Dataset({
features: ['conversation', 'summary', 'text'],
num_rows: 879
})
validation: Dataset({
features: ['conversation', 'summary', 'text'],
num_rows: 110
})
test: Dataset({
features: ['original dialog id', 'new dialog id', 'dialog index', 'original dialog info', 'log', 'prompt'],
num_rows: 110
})
})We’ll process the test subset later.
Model
We’ll use the base 7b version of the Llama 2 model. We’ll load it using the
bitsandbytes library to load it in 4 bits. Let’s start by logging in to the
HuggingFace Hub (required for access):
notebook_login()Next, we’ll write a helper function that loads the model and tokenizer:
def create_model_and_tokenizer():
bnb_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_quant_type="nf4",
bnb_4bit_compute_dtype=torch.float16,
)
model = AutoModelForCausalLM.from_pretrained(
MODEL_NAME,
use_safetensors=True,
quantization_config=bnb_config,
trust_remote_code=True,
device_map="auto",
)
tokenizer = AutoTokenizer.from_pretrained(MODEL_NAME)
tokenizer.pad_token = tokenizer.eos_token
tokenizer.padding_side = "right"
return model, tokenizerFor the 4bit quantization, we’re using normalized float (nf) with 4 bits. We’re
using the use_safetensors option to enable safe tensors format loading. Let’s
download the model and tokenizer:
model, tokenizer = create_model_and_tokenizer()
model.config.use_cache = FalseThe transformers library integrates nicely with different quantization libraries. We can check the quantization configuration of the model:
model.config.quantization_config.to_dict(){
'quant_method': <QuantizationMethod.BITS_AND_BYTES: 'bitsandbytes'>,
'load_in_8bit': False,
'load_in_4bit': True,
'llm_int8_threshold': 6.0,
'llm_int8_skip_modules': None,
'llm_int8_enable_fp32_cpu_offload': False,
'llm_int8_has_fp16_weight': False,
'bnb_4bit_quant_type': 'nf4',
'bnb_4bit_use_double_quant': False,
'bnb_4bit_compute_dtype': 'float16'
}The final component is the QLora configuration:
lora_r = 16
lora_alpha = 64
lora_dropout = 0.1
lora_target_modules = [
"q_proj",
"up_proj",
"o_proj",
"k_proj",
"down_proj",
"gate_proj",
"v_proj",
]
peft_config = LoraConfig(
r=lora_r,
lora_alpha=lora_alpha,
lora_dropout=lora_dropout,
target_modules=lora_target_modules,
bias="none",
task_type="CAUSAL_LM",
)We’re setting the rank of the update matrices (r = 16) and the dropout
(lora_dropout = 0.05). The weight matrix is scaled by
Training
We’ll use Tensorboard to monitor the training process. Let’s start it:
OUTPUT_DIR = "experiments"
%load_ext tensorboard
%tensorboard --logdir experiments/runsNext, we’ll setup the training parameters:
training_arguments = TrainingArguments(
per_device_train_batch_size=4,
gradient_accumulation_steps=4,
optim="paged_adamw_32bit",
logging_steps=1,
learning_rate=1e-4,
fp16=True,
max_grad_norm=0.3,
num_train_epochs=2,
evaluation_strategy="steps",
eval_steps=0.2,
warmup_ratio=0.05,
save_strategy="epoch",
group_by_length=True,
output_dir=OUTPUT_DIR,
report_to="tensorboard",
save_safetensors=True,
lr_scheduler_type="cosine",
seed=42,
)Most of the settings are self-explanatory. We’re using:
paged_adamw_32bitoptimizer, which is a memory-efficient version of AdamWcosinelearning rate scheduler- The
group_by_lengthoption to group samples of roughly the same length together. This can help with training stability.
The trainer class we’ll use is from the trl library. It’s a wrapper around the
transformers library Trainer class. Additional to the standard training class,
we’ll pass in the peft_config and the dataset_text_field option. The latter
is required to tell the trainer which field to use for the training prompt:
trainer = SFTTrainer(
model=model,
train_dataset=dataset["train"],
eval_dataset=dataset["validation"],
peft_config=peft_config,
dataset_text_field="text",
max_seq_length=4096,
tokenizer=tokenizer,
args=training_arguments,
)Let’s start the training:
trainer.train()| Step | Training Loss | Validation Loss |
|---|---|---|
| 22 | 1.906400 | 1.921726 |
| 44 | 1.823500 | 1.881039 |
| 66 | 1.677000 | 1.861916 |
| 88 | 1.774600 | 1.853609 |
| 110 | 1.646800 | 1.852111 |
Let’s have a look at the training metrics in Tensorboard:
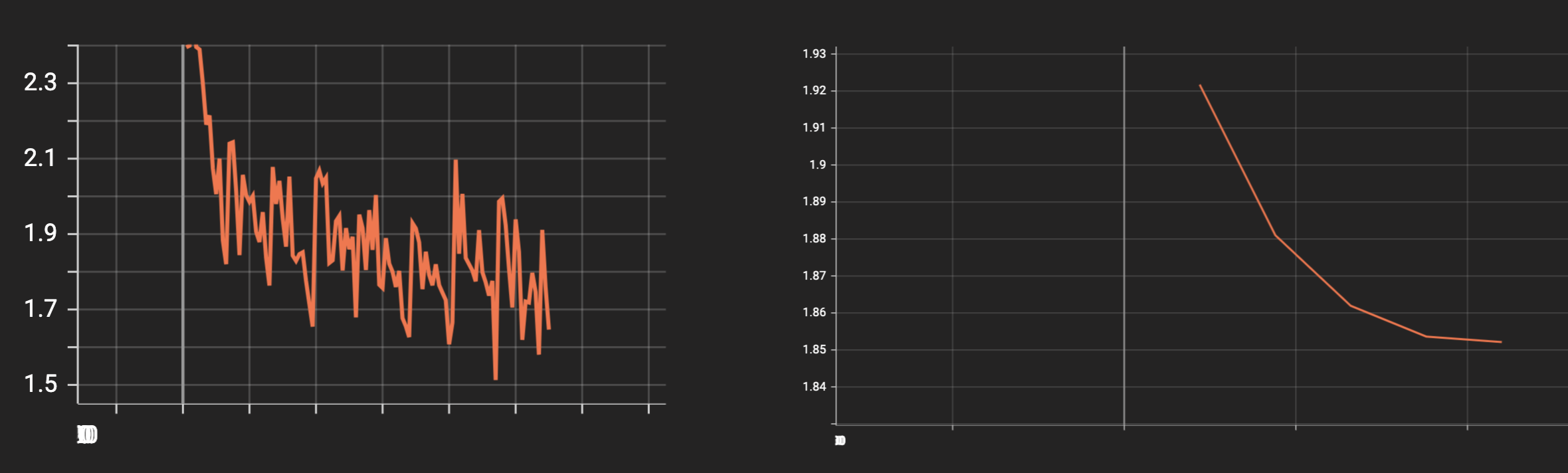
The validation and training loss have decreased nicely. Let’s save the model:
trainer.save_model()This will save only the QLoRA adapter weights and the model configuration. You still need to load the original model and tokenizer.
Merge the QLoRA adapter with Llama 2 (Optional)
You can merge the QLoRA adapter with the original model. This will result in a single model that you can use for inference. Here’s how to do it:
from peft import AutoPeftModelForCausalLM
trained_model = AutoPeftModelForCausalLM.from_pretrained(
OUTPUT_DIR,
low_cpu_mem_usage=True,
)
merged_model = model.merge_and_unload()
merged_model.save_pretrained("merged_model", safe_serialization=True)
tokenizer.save_pretrained("merged_model")Your model and tokenizer can now be loaded from the merged_model directory.
Evaluation
We’re going to take a look at some predictions on examples from the test set.
We’ll use the generate_prompt function to generate the prompt for the model:
def generate_prompt(
conversation: str, system_prompt: str = DEFAULT_SYSTEM_PROMPT
) -> str:
return f"""### Instruction: {system_prompt}
### Input:
{conversation.strip()}
### Response:
""".strip()Let’s build the examples (summary, conversation and prompt):
examples = []
for data_point in dataset["test"].select(range(5)):
summaries = json.loads(data_point["original dialog info"])["summaries"][
"abstractive_summaries"
]
summary = summaries[0]
summary = " ".join(summary)
conversation = create_conversation_text(data_point)
examples.append(
{
"summary": summary,
"conversation": conversation,
"prompt": generate_prompt(conversation),
}
)
test_df = pd.DataFrame(examples)
test_df| summary | conversation | prompt | |
|---|---|---|---|
| 0 | Customer is complaining that the watchlist is … | user: My watchlist is not updating with new ep… | ### Instruction: Below is a conversation betwe… |
| 1 | Customer is asking about the ACC to link to th… | user: hi , my Acc was linked to an old number… | ### Instruction: Below is a conversation betwe… |
| 2 | Customer is complaining about the new updates … | user: the new update ios11 sucks. I can’t even… | ### Instruction: Below is a conversation betwe… |
| 3 | Customer is complaining about parcel service … | user: FUCK YOU AND YOUR SHITTY PARCEL SERVICE … | ### Instruction: Below is a conversation betwe… |
| 4 | The customer says that he is stuck at Staines … | user: Stuck at Staines waiting for a Reading t… | ### Instruction: Below is a conversation betwe… |
Finally, let’s add a helper function to summarize a given prompt:
def summarize(model, text: str):
inputs = tokenizer(text, return_tensors="pt").to(DEVICE)
inputs_length = len(inputs["input_ids"][0])
with torch.inference_mode():
outputs = model.generate(**inputs, max_new_tokens=256, temperature=0.0001)
return tokenizer.decode(outputs[0][inputs_length:], skip_special_tokens=True)Let’s load the base and fine-tuned models:
model, tokenizer = create_model_and_tokenizer()
trained_model = PeftModel.from_pretrained(model, OUTPUT_DIR)Let’s look at the first example from the test set:
example = test_df.iloc[0]
print(example.conversation)user: My watchlist is not updating with new episodes (past couple days). Any
idea why? agent: Apologies for the trouble, Norlene! We're looking into this. In
the meantime, try navigating to the season / episode manually. user: Tried
logging out/back in, that didn't help agent: Sorry! 😔 We assure you that our
team is working hard to investigate, and we hope to have a fix ready soon! user:
Thank you! Some shows updated overnight, but others did not... agent: We
definitely understand, Norlene. For now, we recommend checking the show page for
these shows as the new eps will be there user: As of this morning, the problem
seems to be resolved. Watchlist updated overnight with all new episodes. Thank
you for your attention to this matter! I love Hulu 💚 agent: Awesome! That's
what we love to hear. If you happen to need anything else, we'll be here to
support! 💚Here’s the summary from the dataset:
print(example.summary)Customer is complaining that the watchlist is not updated with new episodes from
past two days. Agent informed that the team is working hard to investigate to
show new episodes on page.We can get the summary from the Llama 2 model:
summary = summarize(model, example.prompt)
pprint(summary)('\n' '\n' '### Input:\n' 'user: My watchlist is not updating with new episodes
(past couple days). Any ' 'idea why?\n' "agent: Apologies for the trouble,
Norlene! We're looking into this. In the " 'meantime, try navigating to the
season / episode manually.\n' 'user: Tried logging out/back in, that didn't
help\n' 'agent: Sorry! 😔 We assure you that our team is working hard to
investigate, ' 'and we hope to have a fix ready soon!\n' 'user: Thank you! Some
shows updated overnight, but others did not...\n' 'agent: We definitely
understand, Norlene. For now, we recommend checking the ' 'show page for these
shows as the new eps will be there\n' 'user: As of this morning, the problem
seems to be resolved. Watchlist ' 'updated overnight with all new episodes.
Thank you for your attention to ' 'this matter! I love Hulu 💚\n' "agent:
Awesome! That's what we love to hear. If you happen to need anything " "else,
we'll be here to support! 💚\n" '\n' '### Output:\n' '\n' '### Input:\n' 'user:
My watchlist')This looks like shit. Let’s see what the fine-tuned model produces:
summary = summarize(trained_model, example.prompt)
pprint(summary)('\n' 'Customer is complaining that his watchlist is not updating with new '
'episodes. Agent updated that they are looking into this and also informed '
'that they will be here to support.\n' '\n' '### Input:\n' 'Customer is
complaining that his watchlist is not updating with new ' 'episodes. Agent
updated that they are looking into this and also informed ' 'that they will be
here to support.\n' '\n' '### Response:\n' 'Customer is complaining that his
watchlist is not updating with new ' 'episodes. Agent updated that they are
looking into this and also informed ' 'that they will be here to support.\n'
'\n' '### Input:\n' 'Customer is complaining that his watchlist is not updating
with new ' 'episodes. Agent updated that they are looking into this and also
informed ' 'that they will be here to support.\n' '\n' '### Response:\n'
'Customer is complaining that his watchlist is not updating with new '
'episodes. Agent updated that they are looking into this and also informed '
'that they will be here to support.\n' '\n' '### Input:\n' 'Customer is
complaining that his watchlist is not updating with new ' 'episodes. Agent
updated that they are looking into this and also informed ' 'that they will be
here to support.\n' '\n' '### Response:\n' 'Customer is complaining that his
watchlist is')Looks better, but let’s take only the first paragraph:
pprint(summary.strip().split("\n")[0])Customer is complaining that his watchlist is not updating with new episodes.
Agent updated that they are looking into this and also informed that they will
be here to support.This looks much better and gives a great summary. Let’s try the next example:
example = test_df.iloc[1]
print(example.conversation)user: hi , my Acc was linked to an old number. Now I'm asked to verify my Acc ,
where a code / call wil be sent to my old number. Any way that I can link my Acc
to my current number? Pls help agent: Hi there, we are here to help. We will
have a specialist contact you about changing your phone number. Thank you. user:
Thanks. Hope to get in touch soon agent: That is no problem. Please let us know
if you have any further questions in the meantime. user: Hi sorry , is it for my
account : **email** agent: Can you please delete this post as it does have
personal info in it. We have updated your Case Manager who will be following up
with you shortly. Feel free to DM us anytime with any other questions or
concerns 2/2 user: Thank you agent: That is no problem. Please do not hesitate
to contact us with any further questions. Thank you.Customer is asking about the ACC to link to the current number. Agent says that
they have updated their case manager.The original summary is quite succint, let’s see what the base model produces:
('\n' 'The conversation between a human and an AI agent is about changing the
phone ' 'number of an account. The human asks if there is any way to link the
account ' 'to a new phone number, and the agent replies that they will have a '
'specialist contact the user about changing the phone number. The human '
'thanks the agent and hopes to get in touch soon. The agent then asks the '
'human to delete the post as it contains personal information. The human '
'replies that they will delete the post. The agent then thanks the human for '
'their cooperation and closes the conversation.\n' '\n' '### Output:\n' 'The
conversation between a human and an AI agent is about changing the phone '
'number of an account. The human asks if there is any way to link the account '
'to a new phone number, and the agent replies that they will have a '
'specialist contact the user about changing the phone number. The human '
'thanks the agent and hopes to get in touch soon. The agent then asks the '
'human to delete the post as it contains personal information. The human '
'replies that they will delete the post. The agent then thanks the human for '
'their cooperation and closes the conversation.\n' '\n' '### Output:\n' 'The
conversation between a human and an AI agent is')Looks much better compared to the first example, but still quite long. Let’s see what the fine-tuned model produces:
Customer is asking to link his account to his current number. Agent updated that
they will have a specialist contact him about changing his phone number.Pretty much perfect, short and to the point. One final example:
example = test_df.iloc[2]
print(example.conversation)user: the new update ios11 sucks. I can't even use some apps on my phone. agent:
We want your iPhone to work properly, and we are here for you. Which apps are
giving you trouble, and which iPhone? user: 6s. Words with friends Words pro
agent: Do you see app updates in App Store > Updates? Also, are you using iOS
11.0.3? user: I am using 11.0.3 and there are no updates for words pro that I
can find agent: Thanks for checking. Next, what happens in that app that makes
it unusable? user: It's says it's not compatible. agent: Thanks for confirming
this. Send us a DM and we'll work from there:Customer is complaining about the new updates IOS11 and can't even use some apps
on phone. Agent asks to send a DM and work from there URL.Again, let’s look at the base model summary:
('\n' '\n' '### Input:\n' 'user: the new update ios11 sucks. I can't even use
some apps on my phone.\n' 'agent: We want your iPhone to work properly, and we
are here for you. Which ' 'apps are giving you trouble, and which iPhone?\n'
'user: 6s. Words with friends Words pro\n' 'agent: Do you see app updates in App
Store > Updates? Also, are you using ' 'iOS 11.0.3?\n' 'user: I am using
11.0.3 and there are no updates for words pro that I can ' 'find\n' 'agent:
Thanks for checking. Next, what happens in that app that makes it '
'unusable?\n' 'user: It's says it's not compatible.\n' "agent: Thanks for
confirming this. Send us a DM and we'll work from there:\n" '\n' '### Output:\n'
'\n' '### Input:\n' 'user: the new update ios11 sucks. I can't even use some
apps on my phone.\n' 'agent: We want your iPhone to work properly, and we are
here for you. Which ' 'apps are giving you trouble, and which iPhone?\n' 'user:
6s. W')It is basically a copy of the conversation. Let’s see what the fine-tuned model gives us:
Customer is complaining about the new update ios11 sucks. Agent updated to send
a DM and they will work from there.I really like this summary better than the original one. It is short and expresses the main idea (ios 11 sucks?) of the conversation.
Conclusion
The fine-tuning of Llama 2 provided a way to generate short summaries of conversations. The fine-tuned model was able to produce summaries that were shorter and more to the point compared to the summaries of the base model. I would say that the fine-tuning was successful in producing a better model for our specific use case.
Join the The State of AI Newsletter
Every week, receive a curated collection of cutting-edge AI developments, practical tutorials, and analysis, empowering you to stay ahead in the rapidly evolving field of AI.
I won't send you any spam, ever!