CryptoGPT: Crypto Twitter Sentiment Analysis
Welcome to the CryptoGPT tutorial! In this tutorial, we'll dive into a fascinating project that combines Streamlit, ChatGPT, and LangChain to analyze the sentiment of tweets related to cryptocurrencies. By utilizing Streamlit, we'll create a user-friendly interface that allows us to interact with our sentiment analysis application effortlessly.
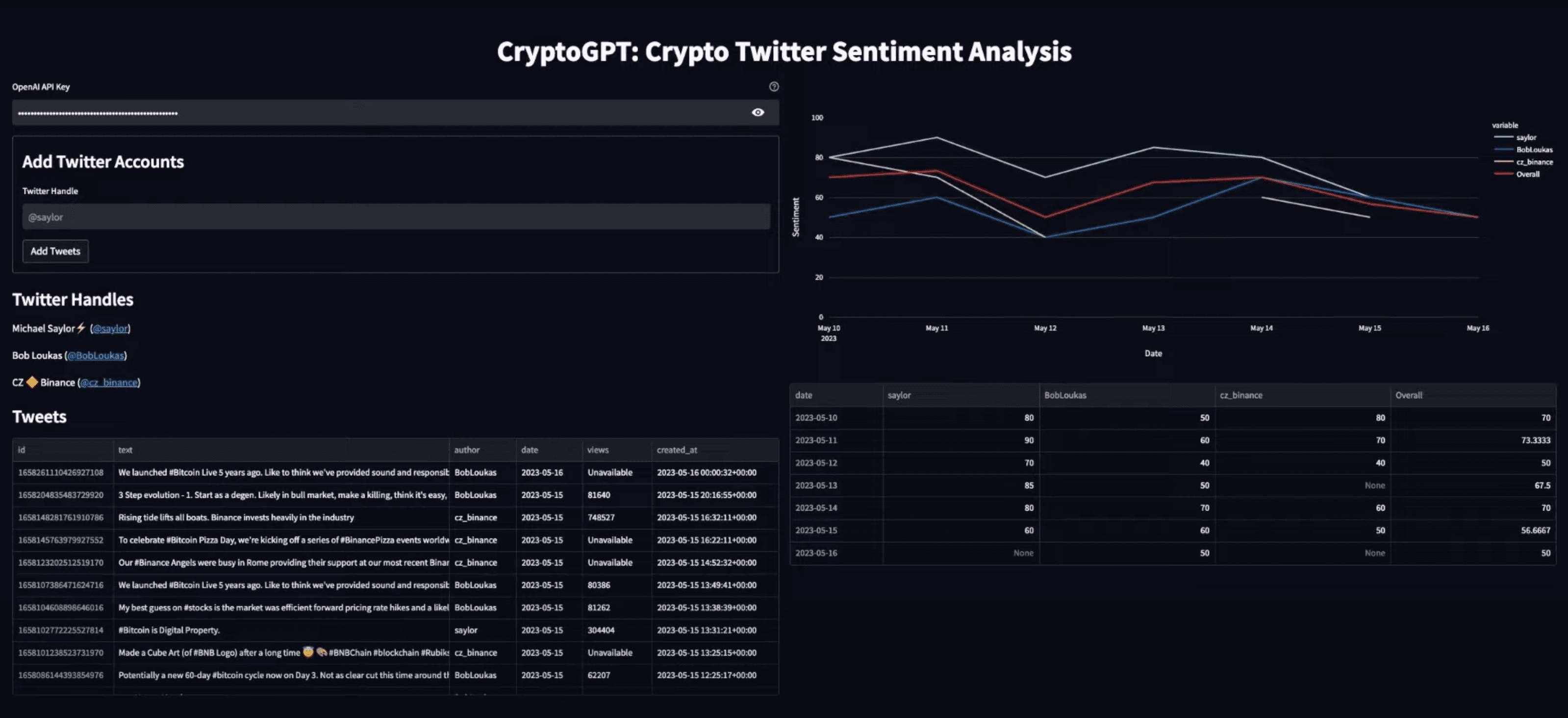
Welcome to the CryptoGPT! In this tutorial, we'll dive into a fascinating project that combines Streamlit, ChatGPT, and LangChain to analyze the sentiment of tweets related to cryptocurrencies. By utilizing Streamlit, we'll create a user-friendly interface that allows us to interact with our sentiment analysis application effortlessly.
By constructing a well-crafted prompt and utilizing ChatGPT's capabilities, we'll be able to generate a sentiment score for each tweet. Each sentiment score will be between 0 (bearish) and 100 (bullish). Let's start building!
Live Demo
The project is hosted on Streamlit Cloud. Try it out: CryptoGPT
Project Setup
We'll use Python 3.11.3 for this project, and the directory structure will be
as follows:
.├── .flake8├── .gitignore├── .python-version├── .vscode│ └── settings.json├── main.py├── requirements.txt└── sentiment_analyzer.pyLibraries
Let's install all of the libraries we'll need for this project:
pip install -U pippip install black isort langchain openai pandas plotly tweety-nsConfig
We'll use black and isort for formatting and import sorting. Additionally,
we'll configure VSCode for the project:
{ "python.formatting.provider": "black", "[python]": { "editor.formatOnSave": true, "editor.codeActionsOnSave": { "source.organizeImports": true } }, "isort.args": ["--profile", "black"]}[flake8]max-line-length = 120Streamlit
Streamlit1 is an open-source Python library designed for building custom web applications with ease. It allows us to create interactive and visually appealing data-driven applications using Python. With Streamlit, we can quickly transform our data analysis code into shareable web applications, making it ideal for our sentiment analysis project. Let's leverage the power of Streamlit to create a seamless and user-friendly interface for analyzing the sentiment of cryptocurrency tweets.
Get Tweets
To fetch tweets for our analysis, we'll make use of the tweety2 library. This library interacts with Twitter's frontend API to retrieve the desired tweets:
from tweety.bot import Twitter
twitter_client = Twitter()Now, let's fetch some tweets from Elon Musk's Twitter account:
tweets = twitter_client.get_tweets("elonmusk")for tweet in tweets: print(tweet.text) print()Spaces interview with @davidfaber starting now
Tesla shareholder meeting underway
As more satellites & ground stations are added, latency & jitter willimprove. Goal is <20ms latency.
Soros reminds me of Magneto
Tesla Powerwall does the seem for individual homes (if you have the backupswitch installed) https://t.co/mY2WHe1KE1We can remove unnecessary elements like URLs, new lines, and multiple spaces from the tweets, as they are not relevant for our sentiment analysis and will save tokens for ChatGPT:
import re
def clean_tweet(text: str) -> str: text = re.sub(r"http\S+", "", text) text = re.sub(r"www.\S+", "", text) return re.sub(r"\s+", " ", text)The first two lines use re.sub() to remove any URLs starting with "http://" or
"www" from the text. The third line replaces consecutive whitespace characters
(such as spaces, tabs, and new lines) with a single space.
We'll use a dataframe to organize and easily visualize the tweets:
from datetime import datetimefrom typing import Dict, List
import pandas as pdfrom tweety.types import Tweet
def create_dataframe_from_tweets(tweets: List[Tweet]) -> pd.DataFrame: rows = [] for tweet in tweets: clean_text = clean_tweet(tweet.text) if len(clean_text) == 0: continue rows.append( { "id": tweet.id, "text": clean_text, "author": tweet.author.username, "date": str(tweet.date.date()), "created_at": tweet.date, "views": tweet.views, } )
df = pd.DataFrame( rows, columns=["id", "text", "author", "date", "views", "created_at"] ) df.set_index("id", inplace=True) if df.empty: return df today = datetime.now().date() df = df[ df.created_at.dt.date > today - pd.to_timedelta("7day") ] return df.sort_values(by="created_at", ascending=False)This create_dataframe_from_tweets function iterates over each tweet, cleans
the text using the clean_tweet function, and adds relevant information such as
tweet ID, text, author, date, views, and creation timestamp to a dictionary.
These dictionaries are used to create a DataFrame with tweets from the past 7
days.
Let's try it out:
df = create_dataframe_from_tweets(tweets)df.head()| id | text | author | date | views | created_at |
|---|---|---|---|---|---|
| 1658564606984441859 | Tesla shareholder meeting underway | elonmusk | 2023-05-16 | 8244078 | 2023-05-16 20:06:31+00:00 |
| 1658525853934813201 | As more satellites & ground stations are added, latency & jitter will improve. Goal is <20ms latency. | elonmusk | 2023-05-16 | 8907366 | 2023-05-16 17:32:32+00:00 |
| 1658291808592629761 | Soros reminds me of Magneto | elonmusk | 2023-05-16 | 39937506 | 2023-05-16 02:02:31+00:00 |
| 1658284090691338241 | Tesla Powerwall does the seem for individual homes (if you have the backup switch installed) | elonmusk | 2023-05-16 | 17370816 | 2023-05-16 01:31:51+00:00 |
Tweet Data UI
Our UI will have a straightforward design, with a split-screen layout consisting of two columns. The left column will be dedicated to loading the data:
col1, col2 = st.columns(2)We require two pieces of information from the user - the OpenAI API key and the Twitter handles:
with col1: st.text_input( "OpenAI API Key", type="password", key="api_key", placeholder="sk-...4242", help="Get your API key: https://platform.openai.com/account/api-keys", )
with st.form(key="twitter_handle_form", clear_on_submit=True): st.subheader("Add Twitter Accounts", anchor=False) st.text_input( "Twitter Handle", value="", key="twitter_handle", placeholder="@saylor" ) submit = st.form_submit_button(label="Add Tweets", on_click=on_add_author)
if st.session_state.twitter_handles: st.subheader("Twitter Handles", anchor=False) for handle, name in st.session_state.twitter_handles.items(): handle = "@" + handle st.markdown(f"{name} ([{handle}](https://twitter.com/{handle}))")
st.subheader("Tweets", anchor=False)
st.dataframe( create_dataframe_from_tweets(st.session_state.tweets), use_container_width=True )We have a password input field for the user to enter their OpenAI API key, and a
form to add Twitter handles. The form has an input field where the user can
enter a Twitter handle, and a button to add the handle and retrieve tweets. We
also display tweet authors in a list. Finally, there is a section displaying the
tweets in a dataframe format using the create_dataframe_from_tweets function
(defined previously).
Let's take a look at how we add tweets:
def on_add_author(): twitter_handle = st.session_state.twitter_handle if twitter_handle.startswith("@"): twitter_handle = twitter_handle[1:] if twitter_handle in st.session_state.twitter_handles: return all_tweets = twitter_client.get_tweets(twitter_handle) if len(all_tweets) == 0: return st.session_state.twitter_handles[twitter_handle] = all_tweets[0].author.name st.session_state.tweets.extend(all_tweets) st.session_state.author_sentiment[twitter_handle] = analyze_sentiment( twitter_handle, st.session_state.tweets )The on_add_author function is triggered when the user clicks the "Add Tweets"
button after entering a Twitter handle. It removes the "@" symbol from the
handle if present, checks if the handle is already added, fetches all the tweets
for that handle, and adds the data to the session state.
Finally, analyzes the sentiment of the tweets using the analyze_sentiment
function and stores it in the session state.
Sentiment Analysis with ChatGPT
To analyze crypto sentiment using ChatGPT, we will provide it with the following prompt:
PROMPT_TEMPLATE = """You're a cryptocurrency trader with 10+ years of experience. You always followthe trend and follow and deeply understand crypto experts on Twitter. Youalways consider the historical predictions for each expert on Twitter.
You're given tweets and their view count from @{twitter_handle} for specific dates:
{tweets}
Tell how bullish or bearish the tweets for each date are. Use numbers between 0and 100, where 0 is extremely bearish and 100 is extremely bullish.
Use a JSON using the format:
date: sentiment
Each record of the JSON should give the aggregate sentiment for that date.Return just the JSON. Do not explain."""The prompt sets the context of ChatGPT as an experienced cryptocurrency trader
who relies on Twitter experts and considers historical predictions. It provides
a variable {twitter_handle} for the Twitter handle and {tweets} for the
tweet data with view counts.
The task is to analyze the sentiment of the tweets for each date and provide a JSON output containing the aggregate sentiment for each date. The sentiment values should range from 0 (extremely bearish) to 100 (extremely bullish). We require that the model doesn't provide any other output.
Let's use the prompt:
def analyze_sentiment(twitter_handle: str, tweets: List[Tweet]) -> Dict[str, int]: chat_gpt = ChatOpenAI(temperature=0, model_name="gpt-3.5-turbo") prompt = PromptTemplate( input_variables=["twitter_handle", "tweets"], template=PROMPT_TEMPLATE )
sentiment_chain = LLMChain(llm=chat_gpt, prompt=prompt) response = sentiment_chain( { "twitter_handle": twitter_handle, "tweets": create_tweet_list_for_prompt(tweets, twitter_handle), } ) return json.loads(response["text"])The function analyze_sentiment takes a Twitter handle and a list of tweets as
inputs. It creates an instance of the ChatOpenAI class, specifying the model as
ChatGPT. It also creates a prompt and provides the variables twitter_handle
and tweets.
We send a request to ChatGPT (via the LLMChain from LangChain) by passing the
Twitter handle and the processed tweet list as input variables. Finally, the
function returns the parsed JSON object representing the sentiment analysis of
the tweets, with each date mapped to an integer sentiment value.
The final part is this helper function:
def create_tweet_list_for_prompt(tweets: List[Tweet], twitter_handle: str) -> str: df = create_dataframe_from_tweets(tweets) user_tweets = df[df.author == twitter_handle] if user_tweets.empty: return "" if len(user_tweets) > 100: user_tweets = user_tweets.sample(n=100)
text = ""
for tweets_date, tweets in user_tweets.groupby("date"): text += f"{tweets_date}:" for tweet in tweets.itertuples(): text += f"\n{tweet.views} - {tweet.text}" return textThe function creates a dataframe from the tweets using the
create_dataframe_from_tweets function. It then keeps only the tweets authored
by the given Twitter handle and limits them to 100.
The function then appends tweet texts and view counts grouped by date to a
text variable.
Visualize Sentiment
We'll utilize Plotly to visualize the sentiment. We can generate a line chart to visualize the sentiment trends. Additionally, we'll display a dataframe that contains the sentiment data:
with col2: sentiment_df = create_sentiment_dataframe(st.session_state.author_sentiment) if not sentiment_df.empty: fig = px.line( sentiment_df, x=sentiment_df.index, y=sentiment_df.columns, labels={"date": "Date", "value": "Sentiment"}, ) fig.update_layout(yaxis_range=[0, 100]) st.plotly_chart(fig, theme="streamlit", use_container_width=True)
st.dataframe(sentiment_df, use_container_width=True)Note that we specify the y axis range as [0, 100] to ensure that the sentiment
values are scaled properly.
Let's create the data frame for the sentiment chart:
def create_sentiment_dataframe(sentiment_data: Dict[str, int]) -> pd.DataFrame: date_list = pd.date_range( datetime.now().date() - timedelta(days=6), periods=7, freq="D" ) dates = [str(date) for date in date_list.date] chart_data = {"date": dates}
for author, sentiment_data in sentiment_data.items(): author_sentiment = [] for date in dates: if date in sentiment_data: author_sentiment.append(sentiment_data[date]) else: author_sentiment.append(None) chart_data[author] = author_sentiment
sentiment_df = pd.DataFrame(chart_data) sentiment_df.set_index("date", inplace=True)
if not sentiment_df.empty: sentiment_df["Overall"] = sentiment_df.mean(skipna=True, axis=1) return sentiment_dfOur function generates a list of dates for the past 7 days and initializes the
DataFrame with the dates as the index. Then, it populates it with sentiment
values for each author, filling in missing values with None. Finally, it
calculates the overall sentiment by taking the mean of the sentiment values for
each date (row) as a new column.
Conclusion
In this tutorial, we covered the process of sentiment analysis on cryptocurrency tweets using LangChain and ChatGPT. We learned how to download and preprocess tweets, visualize sentiment data using Plotly, and create a Streamlit application to interact with the sentiment analysis pipeline.
The integration of Streamlit allows us to create an interactive and intuitive interface for users to input Twitter handles, view sentiment analysis results, and visualize the sentiment trends over time.
Complete Code
import jsonimport refrom datetime import datetimefrom typing import Dict, List
import pandas as pdimport streamlit as stfrom langchain.chains import LLMChainfrom langchain.chat_models import ChatOpenAIfrom langchain.prompts import PromptTemplatefrom tweety.types import Tweet
PROMPT_TEMPLATE = """You're a cryptocurrency trader with 10+ years of experience. You always follow the trendand follow and deeply understand crypto experts on Twitter. You always consider the historical predictions for each expert on Twitter.
You're given tweets and their view count from @{twitter_handle} for specific dates:
{tweets}
Tell how bullish or bearish the tweets for each date are. Use numbers between 0 and 100, where 0 is extremely bearish and 100 is extremely bullish.Use a JSON using the format:
date: sentiment
Each record of the JSON should give the aggregate sentiment for that date. Return just the JSON. Do not explain."""
def clean_tweet(text: str) -> str: text = re.sub(r"http\S+", "", text) text = re.sub(r"www.\S+", "", text) return re.sub(r"\s+", " ", text)
def create_dataframe_from_tweets(tweets: List[Tweet]) -> pd.DataFrame: rows = [] for tweet in tweets: clean_text = clean_tweet(tweet.text) if len(clean_text) == 0: continue rows.append( { "id": tweet.id, "text": clean_text, "author": tweet.author.username, "date": str(tweet.date.date()), "created_at": tweet.date, "views": tweet.views, } )
df = pd.DataFrame( rows, columns=["id", "text", "author", "date", "views", "created_at"] ) df.set_index("id", inplace=True) if df.empty: return df df = df[df.created_at.dt.date > datetime.now().date() - pd.to_timedelta("7day")] return df.sort_values(by="created_at", ascending=False)
def create_tweet_list_for_prompt(tweets: List[Tweet], twitter_handle: str) -> str: df = create_dataframe_from_tweets(tweets) user_tweets = df[df.author == twitter_handle] if user_tweets.empty: return "" if len(user_tweets) > 100: user_tweets = user_tweets.sample(n=100)
text = ""
for tweets_date, tweets in user_tweets.groupby("date"): text += f"{tweets_date}:" for tweet in tweets.itertuples(): text += f"\n{tweet.views} - {tweet.text}" return text
def analyze_sentiment(twitter_handle: str, tweets: List[Tweet]) -> Dict[str, int]: chat_gpt = ChatOpenAI(temperature=0, model_name="gpt-3.5-turbo") prompt = PromptTemplate( input_variables=["twitter_handle", "tweets"], template=PROMPT_TEMPLATE )
sentiment_chain = LLMChain(llm=chat_gpt, prompt=prompt) response = sentiment_chain( { "twitter_handle": twitter_handle, "tweets": create_tweet_list_for_prompt(tweets, twitter_handle), } ) return json.loads(response["text"])import osfrom datetime import datetime, timedeltafrom typing import Dict
import pandas as pdimport plotly.express as pximport streamlit as stfrom tweety.bot import Twitter
from sentiment_analyzer import analyze_sentiment, create_dataframe_from_tweets
twitter_client = Twitter()
def on_add_author(): twitter_handle = st.session_state.twitter_handle if twitter_handle.startswith("@"): twitter_handle = twitter_handle[1:] if twitter_handle in st.session_state.twitter_handles: return all_tweets = twitter_client.get_tweets(twitter_handle) if len(all_tweets) == 0: return st.session_state.twitter_handles[twitter_handle] = all_tweets[0].author.name st.session_state.tweets.extend(all_tweets) st.session_state.author_sentiment[twitter_handle] = analyze_sentiment( twitter_handle, st.session_state.tweets )
def create_sentiment_dataframe(sentiment_data: Dict[str, int]) -> pd.DataFrame: date_list = pd.date_range( datetime.now().date() - timedelta(days=6), periods=7, freq="D" ) dates = [str(date) for date in date_list.date] chart_data = {"date": dates}
for author, sentiment_data in sentiment_data.items(): author_sentiment = [] for date in dates: if date in sentiment_data: author_sentiment.append(sentiment_data[date]) else: author_sentiment.append(None) chart_data[author] = author_sentiment
sentiment_df = pd.DataFrame(chart_data) sentiment_df.set_index("date", inplace=True)
if not sentiment_df.empty: sentiment_df["Overall"] = sentiment_df.mean(skipna=True, axis=1) return sentiment_df
st.set_page_config( layout="wide", page_title="CryptoGPT: Crypto Twitter Sentiment Analysis", page_icon="https://cdn.jsdelivr.net/gh/twitter/twemoji@14.0.2/assets/72x72/1f4c8.png",)
st.markdown( "<h1 style='text-align: center'>CryptoGPT: Crypto Twitter Sentiment Analysis</h1>", unsafe_allow_html=True,)
if not "tweets" in st.session_state: st.session_state.tweets = [] st.session_state.twitter_handles = {} st.session_state.api_key = "" st.session_state.author_sentiment = {}
os.environ["OPENAI_API_KEY"] = st.session_state.api_key
col1, col2 = st.columns(2)
with col1: st.text_input( "OpenAI API Key", type="password", key="api_key", placeholder="sk-...4242", help="Get your API key: https://platform.openai.com/account/api-keys", )
with st.form(key="twitter_handle_form", clear_on_submit=True): st.subheader("Add Twitter Accounts", anchor=False) st.text_input( "Twitter Handle", value="", key="twitter_handle", placeholder="@saylor" ) submit = st.form_submit_button(label="Add Tweets", on_click=on_add_author)
if st.session_state.twitter_handles: st.subheader("Twitter Handles", anchor=False) for handle, name in st.session_state.twitter_handles.items(): handle = "@" + handle st.markdown(f"{name} ([{handle}](https://twitter.com/{handle}))")
st.subheader("Tweets", anchor=False)
st.dataframe( create_dataframe_from_tweets(st.session_state.tweets), use_container_width=True )
with col2: sentiment_df = create_sentiment_dataframe(st.session_state.author_sentiment) if not sentiment_df.empty: fig = px.line( sentiment_df, x=sentiment_df.index, y=sentiment_df.columns, labels={"date": "Date", "value": "Sentiment"}, ) fig.update_layout(yaxis_range=[0, 100]) st.plotly_chart(fig, theme="streamlit", use_container_width=True)
st.dataframe(sentiment_df, use_container_width=True)