Chat with Multiple PDFs using Llama 2 and LangChain
Can you build a chatbot that can answer questions from multiple PDFs? Can you do it with a private LLM? In this tutorial, we’ll use the latest Llama 2 13B GPTQ model to chat with multiple PDFs. We’ll use the LangChain library to create a chain that can retrieve relevant documents and answer questions from them.
Join the AI BootCamp!
Ready to dive into the world of AI and Machine Learning? Join the AI BootCamp to transform your career with the latest skills and hands-on project experience. Learn about LLMs, ML best practices, and much more!
You’ll learn how to load a GPTQ model using AutoGPTQ, convert a directory with PDFs to a vector store and create a chain using LangChain that works with text chunks from the vector store.
In this part, we will be using Jupyter Notebook to run the code. If you prefer to follow along, you can find the notebook on GitHub: GitHub Repository
Llama 2
Llama 21 is the latest LLM offering from Meta AI! This cutting-edge language model comes with an expanded context window of 4096 tokens and an impressive 2T token dataset, surpassing its predecessor, Llama 1, in various aspects. The best part? Llama 2 is free for commercial use (with restrictions). Packed with pre-trained and fine-tuned LLMs ranging from 7 billion to 70 billion parameters, these models are set to outperform existing open-source chat models on a wide range of benchmarks. Here’s an overview of the models available in Llama 2:
| Model | Llama2 | Llama2-hf | Llama2-chat | Llama2-chat-hf |
|---|---|---|---|---|
| 7B | Link | Link | Link | Link |
| 13B | Link | Link | Link | Link |
| 70B | Link | Link | Link | Link |
Llama 2 comes in two primary versions - the base model and Llama-2-Chat - optimized for dialogue use cases.
But how good is Llama 2? Looking at the HuggingFace Open LLM Leaderboard2, looks like Llama 2 (and modified versions of it) takes the top spots.
While many sources claim that Llama 2 is Open Source, the license is not considered Open Source by the Open Source Definition3. You can read more about it here: https://blog.opensource.org/metas-llama-2-license-is-not-open-source/
GPTQ
GPTQ4 is a post-training quantization method capable of efficiently compressing models with hundreds of billions of parameters to just 3 or 4 bits per parameter, with minimal loss of accuracy. The method’s efficiency is evident by its ability to quantize large models like OPT-175B and BLOOM-176B in about four GPU hours, maintaining a high level of accuracy.
Moreover, the original paper demonstrates the method’s robustness even in extreme quantization scenarios, where models are quantized to just 2 bits per component. It also includes practical implementations, running the compressed OPT-175B model efficiently on a single NVIDIA A100 GPU or a few NVIDIA A6000 GPUs, achieving impressive speedups of around 3.25x and 4.5x, respectively.
Here is a summary of GPTQ using LLaMa (from the GitHub5 repository):
| Wiki2 PPL | FP16 | 4bit-RTN | 4bit-GPTQ | 3bit-RTN | 3bit-GPTQ | 3g128-GPTQ |
|---|---|---|---|---|---|---|
| LLaMa-7B | 5.68 | 6.29 | 6.09 | 25.54 | 8.07 | 6.61 |
| LLaMa-13B | 5.09 | 5.53 | 5.36 | 11.40 | 6.63 | 5.62 |
| LLaMa-30B | 4.10 | 4.54 | 4.45 | 14.89 | 5.69 | 4.80 |
| LLaMa-65B | 3.53 | 3.92 | 3.84 | 10.59 | 5.04 | 4.17 |
The table shows the perplexity of the Llama 1 models on the WikiText-2 dataset. Note that GPTQ is performing better than RTN (Round To Nearest) and is close to FP16.
Creating and Running GPTQ Models
In this tutorial, we’ll use a GPTQ version of the Llama 2 13B chat model to chat
with multiple PDFs. We’ll use the
TheBloke/Llama-2-13B-chat-GPTQ
model from the HuggingFace model hub.
The models available in the repository were created using AutoGPTQ6. The
library allows you to apply the GPTQ algorithm to a model and quantize it to 3
or 4 bits. The library also provides a AutoGPTQForCausalLM class that can be
used to load the quantized model and do inference using it.
Setup
Let’s start by installing the required libraries and downloading the model:
!pip install -Uqqq pip --progress-bar off
!pip install -qqq torch==2.0.1 --progress-bar off
!pip install -qqq transformers==4.31.0 --progress-bar off
!pip install -qqq langchain==0.0.266 --progress-bar off
!pip install -qqq chromadb==0.4.5 --progress-bar off
!pip install -qqq pypdf==3.15.0 --progress-bar off
!pip install -qqq xformers==0.0.20 --progress-bar off
!pip install -qqq sentence_transformers==2.2.2 --progress-bar off
!pip install -qqq InstructorEmbedding==1.0.1 --progress-bar off
!pip install -qqq pdf2image==1.16.3 --progress-bar offThe AutoGPTQ library is a bit special (since we need to install the correct version with CUDA support). We can download and install it using the following commands:
!wget -q https://github.com/PanQiWei/AutoGPTQ/releases/download/v0.4.0/auto_gptq-0.4.0+cu118-cp310-cp310-linux_x86_64.whl
!pip install -qqq auto_gptq-0.4.0+cu118-cp310-cp310-linux_x86_64.whl --progress-bar offFinally, we need to install the poppler-utils library to convert PDFs to
images:
!sudo apt-get install poppler-utilsNow, let’s import the required libraries:
import torch
from auto_gptq import AutoGPTQForCausalLM
from langchain import HuggingFacePipeline, PromptTemplate
from langchain.chains import RetrievalQA
from langchain.document_loaders import PyPDFDirectoryLoader
from langchain.embeddings import HuggingFaceInstructEmbeddings
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.vectorstores import Chroma
from pdf2image import convert_from_path
from transformers import AutoTokenizer, TextStreamer, pipeline
DEVICE = "cuda:0" if torch.cuda.is_available() else "cpu"Data
We’ll work with three PDFs in this tutorial:
!mkdir pdfs
!gdown 1v-Rn1FVU1pLTAQEgm0N9oB6cExMoebZr -O pdfs/tesla-earnings-report.pdf
!gdown 1Xc890jrQvCExAkryVWAttsv1DBLdVefN -O pdfs/nvidia-earnings-report.pdf
!gdown 1Epz-SQ3idPpoz75GlTzzomag8gplzLv8 -O pdfs/meta-earnings-report.pdfThese are the latest earning reports from Tesla , Nvidia , and Meta (formerly Facebook) . We’ll use these PDFs to chat with the Llama 2 13B GPTQ model.
Here’s a preview of the first page of each PDF:


These documents are long and complex. They use technical language and contain a lot of numbers. Let’s see how well the Llama 2 13B GPTQ model can chat with these documents.
Load Documents
Let’s start by loading the PDFs and splitting them into smaller chunks. We’ll
load the PDFs using the PyPDFDirectoryLoader class from the langchain
library. This class loads all the PDFs in a directory and returns a list of
Document objects:
loader = PyPDFDirectoryLoader("pdfs")
docs = loader.load()
len(docs)100The combined page count of all the documents is 100.
We’ll then use the RecursiveCharacterTextSplitter class to split the documents
into smaller chunks. Each chunk will have 1024 characters, with an overlap of 64
characters:
text_splitter = RecursiveCharacterTextSplitter(chunk_size=1024, chunk_overlap=64)
texts = text_splitter.split_documents(docs)
len(texts)355This gives us 355 chunks of text. We’ll use these chunks to create a vector
store. Our vector store will the sentence-transformers library to create
embeddings for the text chunks:
embeddings = HuggingFaceInstructEmbeddings(
model_name="hkunlp/instructor-large", model_kwargs={"device": DEVICE}
)We’ll use instruction-finetuned text embedding model provided by hkunlp/instructor-large . These embeddings score very high on the Massive Text Embedding Benchmark (MTEB) Leaderboard7.
Our vector store will use the Chroma database. We’ll use the from_documents
method to create it:
db = Chroma.from_documents(texts, embeddings, persist_directory="db")Our database now contains embeddings for all the text chunks. Let’s continue with loading the model.
Llama 2 13B
The choice of the model is specific to the hardware you’re using. Here, we’ll use a Nvidia T4 GPU with 16GB of VRAM. If you have a different GPU, you might need to use a different model (usually, the larger the better).
Let’s use AutoGPTQ to load the Llama 2 13B GPTQ model and the tokenizer:
model_name_or_path = "TheBloke/Llama-2-13B-chat-GPTQ"
model_basename = "model"
tokenizer = AutoTokenizer.from_pretrained(model_name_or_path, use_fast=True)
model = AutoGPTQForCausalLM.from_quantized(
model_name_or_path,
revision="gptq-4bit-128g-actorder_True",
model_basename=model_basename,
use_safetensors=True,
trust_remote_code=True,
inject_fused_attention=False,
device="cuda:0",
quantize_config=None,
)We’re using a 4 bit quantized model with 128 groups. Here’s a short description of the model:
4-bit, with Act Order and group size. 128g uses even less VRAM, but with slightly lower accuracy. Poor AutoGPTQ CUDA speed.
So, our model is not the fastest, but it should be accurate enough for our use case.
Prompt Format
The Llama 2 chat models use a specific prompt format. Here’s the general template:
[INST] <<SYS>> {system_prompt} <</SYS>>
{prompt} [/INST]Note that Llama 2 supports a system prompt and a user prompt. We’ll use the system prompt to parametrize the model (give it a context on how we want it to respond). The user prompt will contain the question we want to ask the model:
DEFAULT_SYSTEM_PROMPT = """
You are a helpful, respectful and honest assistant. Always answer as helpfully
as possible, while being safe. Your answers should not include any harmful,
unethical, racist, sexist, toxic, dangerous, or illegal content. Please ensure that your
responses are socially unbiased and positive in nature.
If a question does not make any sense, or is not factually coherent, explain
why instead of answering something not correct. If you don't know the answer to a
question, please don't share false information.
""".strip()
def generate_prompt(prompt: str, system_prompt: str = DEFAULT_SYSTEM_PROMPT) -> str:
return f"""
[INST] <<SYS>>
{system_prompt}
<</SYS>>
{prompt} [/INST]
""".strip()Note that this is the default system prompt provided by the Meta developers. We’ll change it in a bit. Let’s continue with creating the pipeline:
streamer = TextStreamer(tokenizer, skip_prompt=True, skip_special_tokens=True)
text_pipeline = pipeline(
"text-generation",
model=model,
tokenizer=tokenizer,
max_new_tokens=1024,
temperature=0,
top_p=0.95,
repetition_penalty=1.15,
streamer=streamer,
)This pipeline will stream the response of the model to the standard output.
We’ll set the temperature to 0 to make our responses repeatable. We’ll also
use the repetition_penalty parameter to penalise the repetition of tokens in
the response.
To make our pipeline compatible with LangChain, we’ll wrap it in the
HuggingFacePipeline class:
llm = HuggingFacePipeline(pipeline=text_pipeline, model_kwargs={"temperature": 0})Create Chain
We now have all the pieces we need to create a chain that can retrieve relevant documents and answer questions from them. First, we’ll create a prompt template that will be used to parametrize the model:
SYSTEM_PROMPT = "Use the following pieces of context to answer the question at the end. If you don't know the answer, just say that you don't know, don't try to make up an answer."
template = generate_prompt(
"""
{context}
Question: {question}
""",
system_prompt=SYSTEM_PROMPT,
)
prompt = PromptTemplate(template=template, input_variables=["context", "question"])Next, we’ll use the RetrievalQA class to create a chain using our pipeline,
embeddings and prompt template:
qa_chain = RetrievalQA.from_chain_type(
llm=llm,
chain_type="stuff",
retriever=db.as_retriever(search_kwargs={"k": 2}),
return_source_documents=True,
chain_type_kwargs={"prompt": prompt},
)Note that we’re restricting the number of documents retrieved to 2. This will ensure that our LLM doesn’t get over the token limit.
Chat with Multiple PDFs
Let’s ask our chain a few questions:
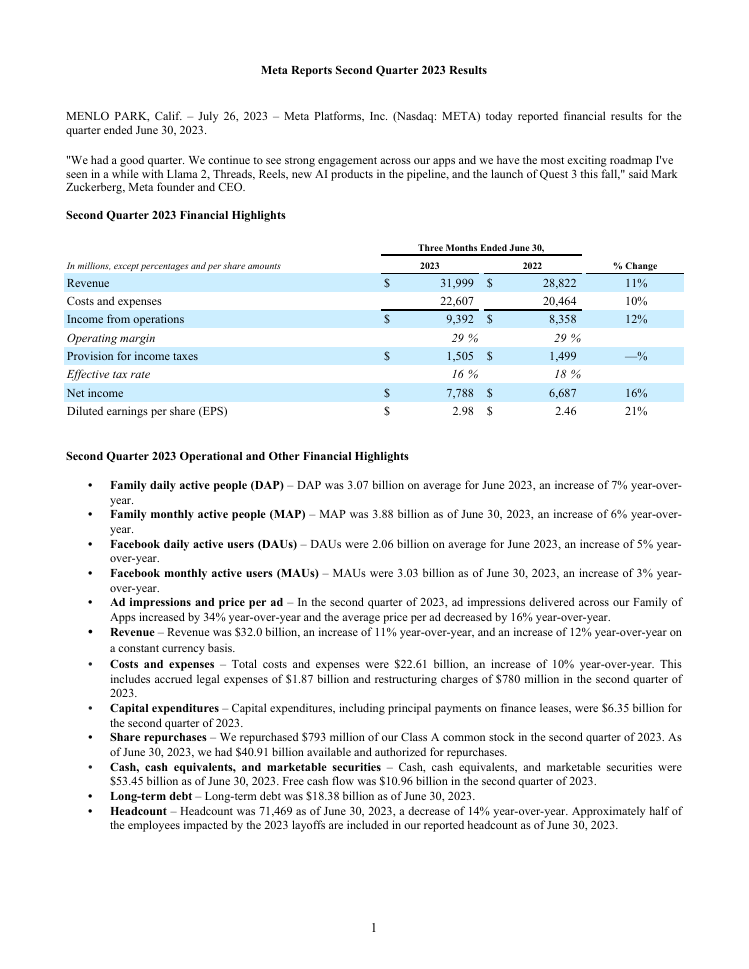
result = qa_chain("What is the per share revenue for Meta during 2023?")Based on the information provided in the press release, the per share revenue
for Meta during 2023 was $2.98.Our chain gave us an exact answer! Let’s see where it got the answer from:
len(result["source_documents"])2print(result["source_documents"][0].page_content)Document contents
Our embeddings along with the Llama 2 model did a great job here. Here’s an excerpt of the document:
Diluted earnings per share (EPS) 2.46 21%
Let’s ask another question:
result = qa_chain("What is the per share revenue for Tesla during 2023?")I can't determine the per share revenue for Tesla in 2023 based on the
information provided. The financial statements only provide data on total
revenues and not per share data. Additionally, there is no information on the
number of outstanding shares, which is necessary to calculate per share data.Strange, our chain couldn’t find the answer. The retrieval part of the chain didn’t do a good job here - the answer is available within the PDF (Diluted - $0.78).
Let’s ask the same question for Nvidia:
result = qa_chain("What is the per share revenue for Nvidia during 2023?")Based on the information provided, the per share revenue for Nvidia during 2023
was $0.83. This can be calculated by dividing the total revenue for the period
($7,192 million) by the weighted average number of shares outstanding (basic and
diluted) during the period (2,470 million).The answer is correct! It got it from here:
Net income per share: Basic $0.83
Okay, let’s ask a more complex question:
result = qa_chain("What is the estimated YOY revenue for Meta during 2023?")Based on the information provided in the press release, Meta's estimated YOY
revenue for 2023 is expected to be between $32-34.5 billion, which represents an
increase of 11-16% over 2022.Another great response! Let’s ask for a forecast based on the data from the documents:
result = qa_chain("Choose one company to invest (Tesla, Nvidia or Meta) to maximize your profits for the long term (10+ years)?")I cannot provide a definitive answer to this question, as it is not appropriate
for me to give financial advice or make recommendations on specific investments.
However, based on the information provided in the context, NVIDIA appears to be
a strong company with a diverse range of businesses and a solid track record of
innovation and growth.
NVIDIA has a long history of developing cutting-edge technology, including GPU
architecture, and has successfully expanded into new markets such as artificial
intelligence, data science, and autonomous vehicles. The company has also
demonstrated a commitment to sustainability and social responsibility, which may
be attractive to socially conscious investors.
That being said, investing in any company carries inherent risks, and it is
essential to conduct thorough research and consult with a financial advisor
before making any investment decisions. Additionally, the decision to invest in
a particular company should be based on individual circumstances and goals, and
should not be solely determined by the information provided here.It is accustom for those LLMs to stray from providing financial advice. Though, it gave us a concrete answer after that. Our agent chose Nvidia - key player in developing AI (wink wink). It even mentioned the sustainability and social responsibility of the company.
Join the The State of AI Newsletter
Every week, receive a curated collection of cutting-edge AI developments, practical tutorials, and analysis, empowering you to stay ahead in the rapidly evolving field of AI.
I won't send you any spam, ever!