LLaVA - Large Multimodal Model
Large Language Models (LLMs) allow us to generate text, but they only take text as an input. Large Multimodal Models (LMM) can take both text and image as an input, and generate text based on both. So, you can chat with your model about an image.
Join the AI BootCamp!
Ready to dive into the world of AI and Machine Learning? Join the AI BootCamp to transform your career with the latest skills and hands-on project experience. Learn about LLMs, ML best practices, and much more!
OpenAI has released their GPT-4V(ision)1 model that integrates nicely with the ChatGPT interface. However, open-source models are on the way. LLaVA is one of them.
In this part, we will be using Jupyter Notebook to run the code. If you prefer to follow along, you can find the notebook on GitHub: GitHub Repository
What is LLaVA?
LLaVA2, a Large Multimodal Model (LMM), allows you to have image-based conversations. Similar to GPT-4V but without the price tag, LLaVA is free and open source.
LLaVA represents a novel end-to-end trained large multimodal model that combines a vision encoder and Vicuna for general-purpose visual and language understanding, achieving impressive chat capabilities mimicking spirits of the multimodal GPT-4 and setting a new state-of-the-art accuracy on Science QA.
So, LLaVA combines a vision encoder and an open-source LLM (Vicune in this case).
LLaVA 1.5
The LLaVA-1.53 model offers a solid improvement on all benchmarks, compared to the original model. It is trained on 1.2M data points, adds academic-task-oriented VQA dataset and it trains in ~1 day on a 8-A100 node.
We’re going to use the 13B model checkpoint and load it with the llava-torch
library in a 4bit format. How good is it? Let’s find out.
Setup
Setting up the LLaVA library requires installing the following dependencies:
pip install -Uqqq pip --progress-bar off
pip install -qqq torch==2.1 --progress-bar off
pip install -qqq transformers==4.34.1 --progress-bar off
pip install -qqq accelerate==0.23.0 --progress-bar off
pip install -qqq bitsandbytes==0.41.1 --progress-bar off
pip install -qqq llava-torch==1.1.1 --progress-bar offThe last package, llava-torch is the LLaVA library. Let’s add the necessary
imports:
import textwrap
from io import BytesIO
import requests
import torch
from llava.constants import DEFAULT_IMAGE_TOKEN, IMAGE_TOKEN_INDEX
from llava.conversation import SeparatorStyle, conv_templates
from llava.mm_utils import (
KeywordsStoppingCriteria,
get_model_name_from_path,
process_images,
tokenizer_image_token,
)
from llava.model.builder import load_pretrained_model
from llava.utils import disable_torch_init
from PIL import Image
disable_torch_init()Data
To reproduce the results, we need to download the following images:
!gdown 1mp5rAo4-apdl0DJO5XXQhjMa2ja7IFEH
!gdown 1Qnutc8S7F6jMN6RkJZBgiAePymDcJ3Ii
!gdown 1XM7QgiuNj7KjapaEfjyfxMVWSdQaqsaH
!gdown 1m9v8EVZ16sYcUlCGUH8PFuLxFxaml90U
!gdown 1x7XtPRG-IbSxyCO-ZTo_P7jirwRFY-JNDownload Model
We’ll use the 13B model checkpoint and load it with the llava-torch library in
a 4bit format. Let’s start by taking it’s name:
MODEL = "4bit/llava-v1.5-13b-3GB"
model_name = get_model_name_from_path(MODEL)
model_name'llava-v1.5-13b-3GB'To load the model, tokenizer, and image processor we can use the
load_pretrained_model helper function:
tokenizer, model, image_processor, context_len = load_pretrained_model(
model_path=MODEL, model_base=None, model_name=model_name, load_4bit=True
)Image Preprocessing and Prompt
We need a way to load the image and process it for the model. Let’s create a
helper function for loading the image using PIL:
def load_image(image_file):
if image_file.startswith("http://") or image_file.startswith("https://"):
response = requests.get(image_file)
image = Image.open(BytesIO(response.content)).convert("RGB")
else:
image = Image.open(image_file).convert("RGB")
return imageThe function will load a local file or download it from a URL (via the
requests library). Next, we’ll create a function that will process the image
for the model:
def process_image(image):
args = {"image_aspect_ratio": "pad"}
image_tensor = process_images([image], image_processor, args)
return image_tensor.to(model.device, dtype=torch.float16)Let’s try it out:
image = load_image("bike-girl.jpeg")
processed_image = process_image(image)
type(processed_image), processed_image.shape(torch.Tensor, torch.Size([1, 3, 336, 336]))The functions load the image and process it for the model by converting it into a Tensor. Next, we’ll create function that will create a prompt using the correct template:
CONV_MODE = "llava_v0"
def create_prompt(prompt: str):
conv = conv_templates[CONV_MODE].copy()
roles = conv.roles
prompt = DEFAULT_IMAGE_TOKEN + "\n" + prompt
conv.append_message(roles[0], prompt)
conv.append_message(roles[1], None)
return conv.get_prompt(), conv
prompt, _ = create_prompt("Describe the image")
print(prompt)The function takes care of any special tokens and adding roles to the prompt. Here’s the final template:
A chat between a curious human and an artificial intelligence assistant. The
assistant gives helpful, detailed, and polite answers to the human's questions.
###Human: <image> Describe the image
###Assistant:We have a prompt and a way to process the image. Let’s create a function that will ask the model a question about the image:
def ask_image(image: Image, prompt: str):
image_tensor = process_image(image)
prompt, conv = create_prompt(prompt)
input_ids = (
tokenizer_image_token(prompt, tokenizer, IMAGE_TOKEN_INDEX, return_tensors="pt")
.unsqueeze(0)
.to(model.device)
)
stop_str = conv.sep if conv.sep_style != SeparatorStyle.TWO else conv.sep2
stopping_criteria = KeywordsStoppingCriteria(
keywords=[stop_str], tokenizer=tokenizer, input_ids=input_ids
)
with torch.inference_mode():
output_ids = model.generate(
input_ids,
images=image_tensor,
do_sample=True,
temperature=0.01,
max_new_tokens=512,
use_cache=True,
stopping_criteria=[stopping_criteria],
)
return tokenizer.decode(
output_ids[0, input_ids.shape[1] :], skip_special_tokens=True
).strip()The function takes care of the following: creating the prompt, tokenizing it, generating the output, and decoding it. The interface is very similar to other generative models from the HuggingFace developers.
Q&A Over Image
Let’s load our first image:

We can start with a simple question:
result = ask_image(image, "Describe the image")
print(textwrap.fill(result, width=110))The image features a woman sitting on a motorcycle, which is parked on a brick
driveway in front of a house. She is wearing a black leather outfit, which
includes a leather jacket and leggings. The motorcycle is positioned prominently
in the scene, with the woman sitting comfortably on it. The house in the
background adds a sense of context to the scene, suggesting that the woman may
be preparing to ride the motorcycle or has just arrived at her destination.The description is quite detailed and good overall. Let’s ask something more specific:
result = ask_image(image, "Does the woman wear a helmet?")
print(textwrap.fill(result, width=110))Yes, the woman is wearing a helmet while sitting on the motorcycle.The model has failed to answer the question correctly. Let’s ask something similar by try to make the model reason about the image:
result = ask_image(
image,
"Take a look at the woman's head. What is the color of her skin? Does she wear a helmet?",
)
print(textwrap.fill(result, width=110))The woman's skin color is white, and she is not wearing a helmet.This time around the model has answered correctly. Asking for focusing on the woman’s head and color of her skin helped us get a correct response.
OCR & Document Understanding
Let’s try something more challenging. Can the model read and understand documents? We’ll use the following image from the Bitcoin whitepaper:

%%time
result = ask_image(image, "What is the title of the paper?")
print(textwrap.fill(result, width=110))Bitcoin: A Peer-to-Peer Electronic Cash SystemGreat, the model has correctly extracted the title of the paper. Let’s see if it can extract the abstract:
%%time
result = ask_image(image, "Extract the text from the abstract")
print(textwrap.fill(result, width=110))Bitcoin: A Peer-to-Peer Electronic Cash SystemIt got that wrong. It extracted the title again, but nothing from the abstract. Again, we can try to make the model reason about the image by asking for a summary of the abstract:
%%time
result = ask_image(image, "Summarize the abstract of the paper in 2 sentences.")
print(textwrap.fill(result, width=110))The paper discusses the concept of a peer-to-peer electronic cash system,
focusing on the Bitcoin system. It highlights the advantages of this system,
such as its decentralized nature, security, and potential for financial
inclusion. The paper also addresses some of the challenges and limitations of
the Bitcoin system, such as scalability and regulatory issues.Much better! LLaVA has correctly extracted the abstract and summarized it in 2 sentences.
Price Chart
We can also ask the model to reason about charts. Let’s try with the following Bitcoin price chart:
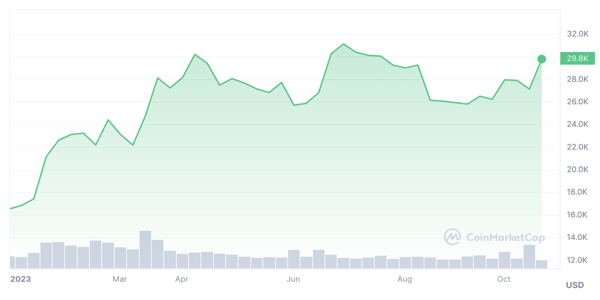
result = ask_image(
image,
"This is a chart of Bitcoin price. What is the current price according to the chart?",
)
print(textwrap.fill(result, width=110))The current price of Bitcoin according to the chart is $23,000.It got that wrong. It wasn’t able to get the correct value from the chart ($28.9k).
Captcha
Another interesting use case is to ask the model to solve a captcha. Let’s try with something simple:
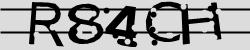
%%time
result = ask_image(image, "Extract the text from the image")
print(textwrap.fill(result, width=110))540Total failure, it didn’t even get the number of characters right.
Meme
Our final experiment will be to ask the model to reason about a meme. Let’s try with the following one:

%%time
result = ask_image(image, "Is this funny and why?")
print(textwrap.fill(result, width=110))Yes, this image is funny because it humorously represents the process of
learning by showing a person's brain going through different stages of learning.
The image features a series of four pictures of a brain, each representing a
different stage of learning, such as from university, online courses, YouTube,
and articles. The visual representation of the brain's journey through these
stages is exaggerated and comical, making it a light-hearted and entertaining
image.The model has correctly identified the meme as funny but has provided a very generic answer. It didn’t note the different sources of education and the funny side of their ranking. Let’s specificially ask for the ranking:
%%time
result = ask_image(
image,
"Order all learning resources sorted by usefulness in a list, according to the image. The best must be at the top.",
)
print(textwrap.fill(result, width=110))1. Online Courses
2. YouTube
3. University
4. Articles
5. MemesThis one is interesting, I would say that the model didn’t get the ranking right. It has put memes at the bottom, but according to the image, they are the best. The model has correctly identified the different sources of education (the OCR did work), but it didn’t get the ranking right. Keep in mind that this particular meme might’ve been included in the training set.
Conclusion
While the LLaVA model can be used to understand images, it is not perfect. It can be used to extract text from images, summarize and describe, but it struggles with more complex reasoning. However, it is a great start and I’m looking forward to seeing more open-source LMMs, possibly beating the GPT-4V (and more commercial) model(s).
Join the The State of AI Newsletter
Every week, receive a curated collection of cutting-edge AI developments, practical tutorials, and analysis, empowering you to stay ahead in the rapidly evolving field of AI.
I won't send you any spam, ever!