Advanced RAG with Llama 3 in LangChain

Chat with a PDF document using Open LLM, Local Embeddings and RAG in LangChain
In this tutorial, we’ll tackle a practical challenge: make a LLM model understand a document and answer questions based on it. We’ll work with a PDF document, breaking it down into manageable parts, transforming these parts into vector embeddings, and storing them for quick retrieval. This approach not only enhances the model’s understanding but also streamlines the search process.
Here’s how our RAG will work:
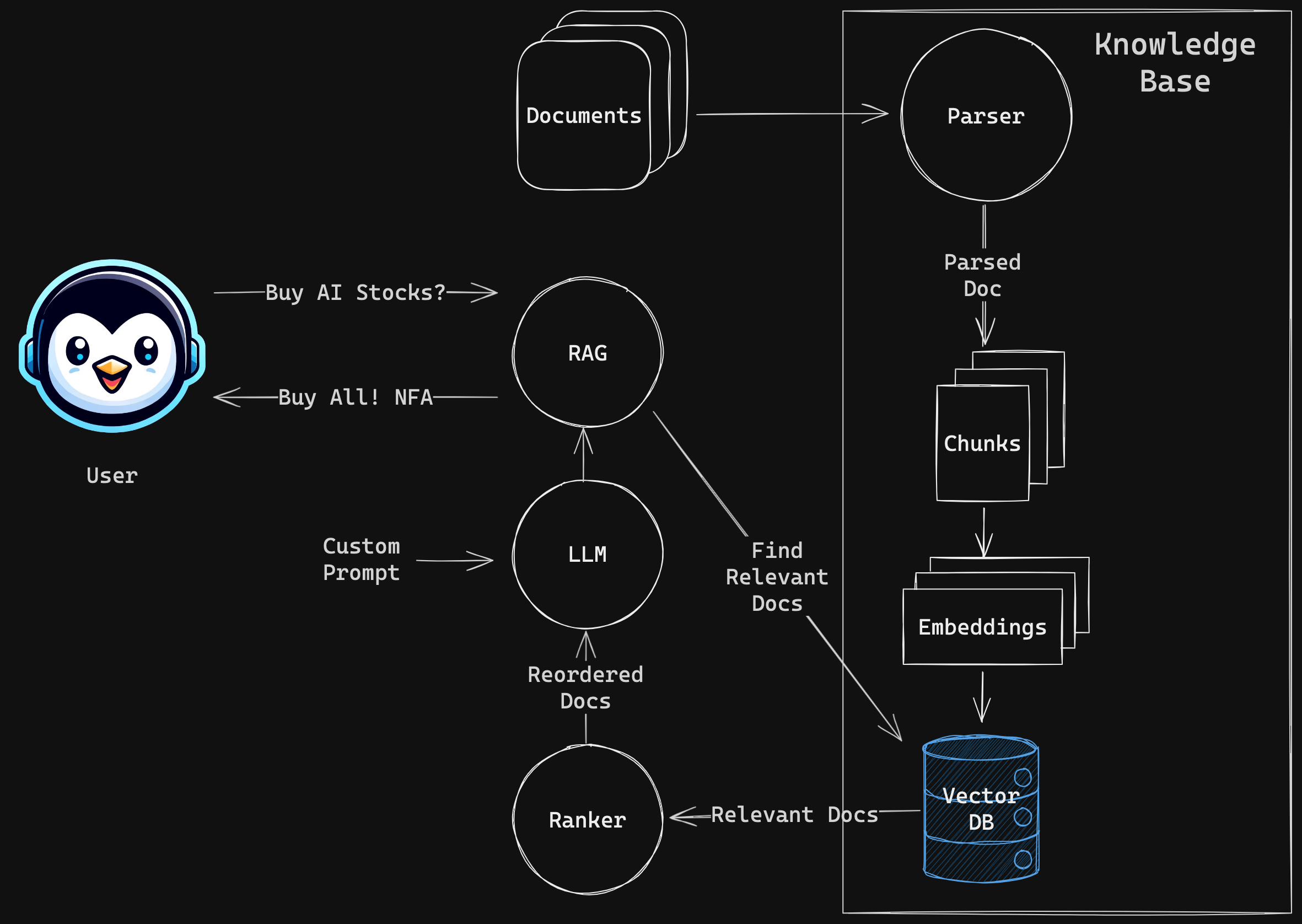
- PDF Document Parsing: We’ll use LlamaParse to convert our PDF document into a text format that our models can understand.
- Creating Vector Embeddings: With FastEmbed, we’ll transform text chunks into vector embeddings. These vectors are like digital fingerprints, unique to each piece of text.
- Storing Vectors: Next, we’ll load these embeddings into a vector database using Qdrant, ensuring they’re ready for quick searching.
- Reranking for Relevance: To make sure the most relevant documents pop up first, we’ll apply Flashrank to reorder our search results.
- Leveraging the Groq API: This powerful API will help our LangChain model process data faster and more efficiently.
- Dynamic Question Answering: Finally, we’ll tie everything together with the RetrievalQA chain in LangChain, enabling our system to answer questions about the document directly.
Tutorial Goals
In this tutorial you will:
- Learn the fundamentals of LangChain
- Store and retrieve vector embeddings from database
- Reorder (if necessary) found documents with reranker
- Ask questions (chat) with a custom PDF document